
 |
개인의 노트북과 스마트폰 등에서 생성형 인공지능(AI) 구현되는 온디바이스 인공지능 시대가 성큼 다가왔다. 연합뉴스 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인공지능은 사람의 과거를 기반으로 미래를 예측할 수 있을까?
과학자들이 도전에 나섰다. 지난해 12월 ‘네이처 컴퓨터과학’에 따르면, 덴마크 공대와 코펜하겐대, 미국 노스이스턴대 합동연구진은 살면서 맞닥뜨리는 여러가지 일들을 토대로 생존률을 예측하는 실험을 진행했다. 연구 대상은 덴마크 국가등록부에 저장된 600만명의 데이터다. 여기엔 나이·주거지, 교육과 소득, 직업과 직장, 근무시간과 같은 개인정보, 신체정보, 질병 등의 건강 정보가 포함돼 있다.
연구 방식이 흥미롭다. 이들은 600만명의 개별 데이터를 정형화된 데이터베이스로 가공하지 않았다. 그대신 이들은 개인의 삶을 서술한 문장을 통째로 이해하는 인공지능 거대언어모델(LLM)을 썼다. ‘2020년 9월, 프란시스코는 엘시노레의 성에서 경비원으로 2만 크로네를 받았다’는 문장을 직업이나 소득 등으로 해체·분류하지 않고 통째로 인공지능에게 학습시켰다. “개인의 삶을 서술한 문장은 유형별로 분류된 데이터보다 더 광범위하고 상세한 정보를 담고 있을 거야”라는 가설을 믿고 연구진은 2008년부터 2015년까지 30~55살 덴마크 국민 600만명의 데이터를 분석한 뒤, 4년 뒤인 2020년까지 생존 가능성을 예측했다. 30~55살을 고른 건, 이 나잇대가 사망률 예측이 어려운 젊은 집단이기 때문이다. 결과도 기대 이상이었다. 조기사망률 예측에선 이들의 ‘라이프투벡’(Life2vec) 모델이 최신 순환신경망(RNN) 모델보다 11% 더 정확한 결과를 보였다. 삶의 변곡점에 중요한 영향을 미치는 성격 검사에서도 라이프투벡 모델은 기존 성격테스트 모델보다 정확한 예측률을 보였다. 엠비티아이(MBTI) 같은 성격 검사도 자연스런 대화로 진행할 수 있다는 얘기다.
한계도 명확하다. 이 연구는 4년 뒤의 생존 확률을 학습에 기반해 제시했다. 변수를 고려해 예측 확률을 높였다고는 하지만, 삶은 예측을 빗나갔다고 해서 무를 순 없다. 자연재해나 교통사고처럼 개인의 사회적 정보나 건강 정보와 무관하게 삶을 뒤흔드는 변수들도 무수하다. 또 연구 대상인 600만명 가운데는 이민자나 행방불명자처럼 이미 삶의 방향이 바뀐 이들도 포함돼 있다. 이를 반영해 실험 결과를 보다 면밀하게 조정해야 하는 작업이 남았다.
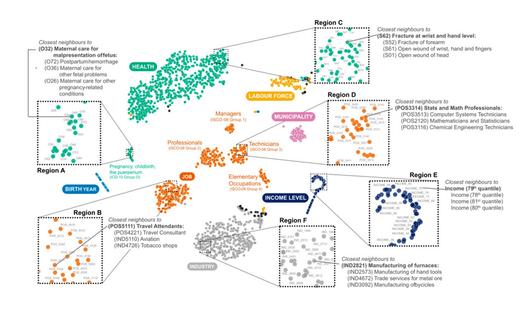 |
연구진은 개인의 삶을 서술한 문장을 통째로 인공지능에게 학습시킨 다음, 그 안에서 직업·수입·거주지나 신상 변화같은 사회·경제적 데이터를 뽑아내 건강 데이터와 연관관계를 분석했다. |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
실험 결과보다 놀라운 건 연구 방법론이다. 이번 연구는 인공지능 트랜스포머 모델을 사회경제적 데이터로 확장했다는 점에서 새롭다. 도시에서 시골로 이사하거나 급여가 오른 사실이 심장마비를 일으킬 확률과 얼마나 연관이 있을까. 사회복지 혜택을 받거나 직장을 옮겼을 때는 어떤 변수가 생길까. 정형화된 수치와 공식으로는 설명하기 어려웠던 삶의 변수를 연구진은 대화하듯 풀어내며 한발짝식 접근했다. 그 결과, 잘 구조화된 데이터보다 확률적으로 의미 있는 결과를 만들어냈다. 학습용 데이터를 사람이 일일이 가공할 필요 없이 자연어 그대로 학습시켰다는 점에서 이번 실험은 거대언어모델(LLM) 기반의 새로운 연구법을 제시했다. 무엇보다 예전에는 데이터라 부르기 힘들었던 일상의 ‘이벤트’들이 삶의 변화와 상관관계를 맺을 수 있다는 가능성을 보여줬다.
미래는 알 수 없지만 삶에 영향을 미치는 요인들을 좀더 명확하게 밝힌다면, 마음의 위로를 넘어 개인별 맞춤 치료도 가능해지지 않을까.
이희욱 미디어랩부장 asadal@hani.co.kr
▶▶한겨레 뉴스레터 모아보기▶▶[기획] 누구나 한번은 1인가구가 된다
이 기사의 카테고리는 언론사의 분류를 따릅니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
