
 |
(사진=셔터스톡) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
중국의 딥시크가 역대 최대 규모의 오픈 소스 대형언어모델(LLM)인 '딥시크-V3(DeepSeek-V3)'를 공개했다. 이 모델은 메타의 '라마 3.1 405B', 알리바바의 '큐원 2.5 72B'와 같은 기존 오픈 소스 모델들을 뛰어넘는 성능을 갖췄으며, 오픈AI의 'GPT-4o'조차 능가한다고 강조했다.
딥시크는 26일(현지시간) 6710억개의 매개변수를 가진 오픈 소스 LLM 딥시크-V3를 출시했다. 이는 4050억 매개변수의 라마 3.1 405B보다 1.5배 이상 큰 규모로, 현재까지 발표된 오픈 소스 모델 중 최대 규모다.
딥시크-V3는 코딩, 번역, 에세이 작성, 이메일 작성 등 설명적 프롬프트에 기반한 다양한 텍스트 작업을 수행할 수 있다.
또 작업 특성에 맞춰 여러 전문 모델로 세분화돼 있으며, '전문가 혼합(MoE)' 방식을 활용해 질문에 적합한 모델을 활성화하거나 결합해 효율성을 극대화한다. 이를 통해 6710억개 매개변수 중 약 340억개만 활성화함으로써 성능은 유지하면서도 추론 비용과 메모리 사용량을 크게 절감할 수 있다.
14조8000억개의 토큰으로 사전 훈련했으며, 최대 12만8000 토큰의 컨텍스트 창을 지원한다. 훈련 과정은 엔비디아 'H800' GPU 기반 데이터센터에서 진행됐으며, 약 557만달러(약 82억원)라는 비교적 적은 비용이 소요됐다. 이는 5억달러(약 7300억원) 이상의 훈련 비용이 추정되는 라마 3.1과 비교했을 때 매우 경제적이라는 평가를 받는다.
기술적 혁신도 돋보인다. '멀티헤드 잠재 어텐션(MLA)' 기술을 사용해 텍스트에서 중요한 세부 사항을 반복적으로 추출함으로써 중요한 정보를 놓칠 가능성을 줄였으며, 멀티토큰 예측(MTP) 기능을 통해 한번에 여러 토큰을 생성함으로써 추론 속도를 향상했다.
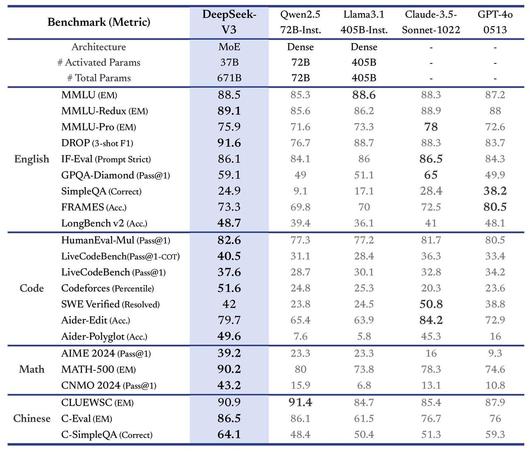 |
벤치마크 결과 (사진=딥시크) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
성능 면에서도 가장 강력한 오픈 소스 모델 중 하나로 자리매김하고 있다. 중국어와 수학 중심의 다양한 벤치마크 테스트에서 뛰어난 점수를 기록했으며, 특히 Math-500 테스트에서 90.2점을 받아 큐원(80점)을 큰 차이로 앞질렀다. 영어 중심 SimpleQA와 FRAMES를 제외한 대부분 벤치마크에서 GPT-4o를 능가하는 결과를 보였다. 다만, 앤트로픽의 '클로드 3.5 소네트'만이 MMLU-Pro, IF-Eval, GPQA-Diamond 등 특정 테스트에서 더 높은 점수를 기록하며 경쟁력을 보였다.
딥시크는 중국을 대표하는 오픈 소스 강자다. 지난달에는 'o1-프리뷰'를 능가한다는 오픈 소스 추론 모델을 가장 먼저 출시하기도 했다.
현재 딥시크-V3는 허깅페이스와 깃허브에서 사용 가능하다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
