
 |
샘 올트먼 오픈AI 최고경영자(CEO)가 지난 1월 18일 스위스 다보스에서 열린 세계경제포럼 연례회의에 참석해 발언하는 모습. AP=연합뉴스 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
이번 계약으로 챗GPT는 이용자와 대화를 주고받는 과정에서 뉴스코프 산하 매체의 기사 등을 합법적으로 활용할 수 있게 됐다. 챗GPT의 답변을 더 똑똑하게 만들 양질의 ‘학습 자료’도 대거 확보했다. 샘 올트먼 오픈AI 최고경영자(CEO)는 성명을 통해 “뉴스코프와의 협력은 저널리즘과 기술 모두에 있어 자랑스러운 순간”이라며 “전 세계 속보 보도를 선도해 온 뉴스코프의 고품질 보도에 대한 사용자들의 접근성을 향상시킬 수 있게 돼 기쁘다”고 밝혔다.
━
이게 왜 중요해?
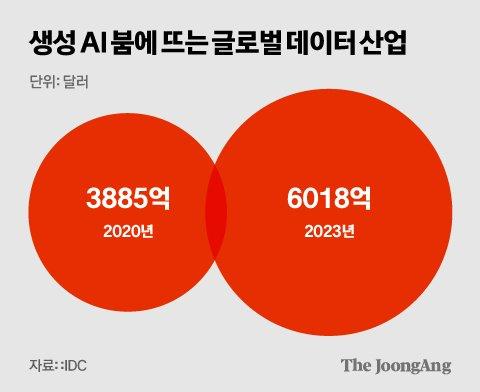
데이터는 생성 AI의 필수 자원이다. 모든 빅테크들은 AI를 학습시킬 고품질 데이터를 원한다. ‘데이터 골드 러시’란 말이 나올 정도로 데이터 확보 경쟁이 치열해지면서 뉴스 콘텐트처럼 정보 출처가 명확하고 신뢰성과 질이 담보되는 데이터 수요는 더 커졌다. AI 리서치 기관 에포크(Epoch)는 2026년이면 AI의 학습용 데이터가 고갈될 거라는 전망을 내놓기도 했다.
상황이 이렇다보니 AI 기업과 콘텐트 기업 간 갈등은 커지고 있다. 언론사들은 AI 회사가 정당한 대가를 지불하지 않고, AI 학습에 온라인에 퍼져있는 기사들을 광범위하게 활용해 돈을 벌고 있다고 주장한다. 특히 AI 시장을 선도하고 있는 오픈AI는 이런 갈등의 최전선에 있다. 뉴욕타임스(NYT)는 지난해 말 오픈 AI를 상대로 “저작권을 침해하고 지식재산권을 도용했다”며 소송을 제기했다.
오픈AI는 무단 사용 주장에 반발하며 NYT의 소송에 대응하고 있지만, 동시에 언론사와 협상을 통해 콘텐트 사용 계약을 맺는 방식으로 해결 방안을 찾고 있다. 기사 무단 사용 여부가 법정에서 가려질 수 있을진 미지수지만, 수없이 많은 콘텐트 기업과 잇따라 소송전을 벌이는 것 역시 부담이 될 수 있다. 오픈AI 입장에선 미리 적정한 대가를 지불하고 마음껏 콘텐트를 쓰는 게 낫다는 판단을 내렸을 수 있다.
 |
김영희 디자이너 |
언론사 역시 일부는 NYT와 같이 법적 대응에 나섰고, 일부는 계약을 통해 수익을 올리는 쪽을 택하고 있다. 뉴욕데일리뉴스·시카고 트리뷴 등 신문사들은 최근 오픈AI 등을 상대로 저작권 소송을 제기했지만, 폴리티코·비즈니스인사이더를 소유한 악셀 스프링거와 AP통신, 파이낸셜타임스 등은 오픈AI와 콘텐트 사용 계약을 체결했다.
이번에 오픈AI와 계약을 맺은 뉴스코프는 앞서 이달 초 구글과도 AI 콘텐트 이용 및 제품 개발 계약을 체결했다. 로버트 톰슨 뉴스코프 CEO는 이날 “(오픈AI와의) 협약은 고급 저널리즘엔 프리미엄이 붙는다는 것을 인정한 것”이라며 “역사적 합의로 디지털 시대의 진실성·미덕·가치에 대한 새로운 기준을 세울 것이라 믿는다”고 밝혔다.
━
한국은 어때?
 |
최수연 네이버 최고경영자(CEO)가 지난해 8월 24일 서울 강남구 그랜드인터컨티넨탈 서울파르나스에서 열린 팀 네이버 콘퍼런스에서 ‘생성형 AI 시대, 모두를 위한 기술 경쟁력’을 주제로 기조연설을 하는 모습. 네이버는 콘퍼런스에서 생성형 AI '하이퍼클로바X'와 이를 기반으로 한 '클로바X' 등을 소개했다. 뉴스1 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
한국에선 뉴스 콘텐트의 합법적 사용료 지급 등에 대한 논의가 제대로 이뤄지지 않고 있다. 한국신문협회는 지난해 말 “네이버의 AI 모델 ‘하이퍼클로바X’가 언론사 동의 없이 뉴스 콘텐트를 학습한 것이 부당하다”며 문제를 제기했고, 공정거래위원회에 네이버 뉴스 제휴 약관 개선을 요구했다. 지난 3월에는 한국신문협회 등 6개 언론 단체가 뜻을 모아 ‘AI 시대 뉴스 저작권 포럼’을 발족하기도 했다.
하지만 네이버는 침묵하고 있다. 지난해 6월부터 AI 학습에 뉴스 콘텐트를 사용하지 않는다고 밝혔지만, 향후 대응에 대해선 공식 입장을 내지 않고 있다. 내부적으로 오픈AI 등 해외 사례를 참고해 대응 방향을 고민 중인 것으로만 알려졌다. AI 개발사가 모인 협회 등에선 “데이터 이용을 위해 하나하나 계약하고 대가를 지불하면 글로벌 경쟁에 뒤처질 수 있다”며 저작권에 구애 받지 않고 학습을 가능하게 해야 한다는 취지의 주장이 나오기도 했다.
상황을 중재해야 할 정부 역시 구체적인 기준은 제시하지 않고 있는 상황. 지난해 12월 문화체육관광부는 ‘생성형 AI 저작권 안내서’를 발표하며 ‘AI 개발사들이 학습용 데이터를 확보할 때 저작권자에게 적절한 보상을 해야 한다’고 권고했지만 어떤 방식으로, 어떻게 보상을 해야 하는 지는 설명하지 않았다. 이 때문에 업계에선 AI 기업과 콘텐트 기업 간 갈등과 혼란이 당분간 이어질 것으로 보고 있다.
■ 더중앙플러스: 막 오른 데이터 전쟁, 디워(D-war)
고품질의 데이터는 AI의 주식(主食)입니다. 글로벌 빅테크 기업들이 앞다퉈 자사 AI를 먹여 살릴 데이터를 구하기 위해 혈투를 벌이고 있죠. 이미 전쟁터가 된 데이터 시장, 그 위에서 펼쳐지는 다양한 경쟁과 주도권을 쥐기 위해 죽어라 뛰고 있는 데이터 기업들을 파헤쳐 봤습니다. 중앙일보 프리미엄 디지털 구독 서비스 The JoongAng Plus ‘팩플 오리지널’(www.joongang.co.kr/article/25250486)에서 확인하실 수 있습니다.
윤정민 기자 yunjm@joongang.co.kr
▶ 중앙일보 / '페이스북' 친구추가
▶ 넌 뉴스를 찾아봐? 난 뉴스가 찾아와!
ⓒ중앙일보(https://www.joongang.co.kr), 무단 전재 및 재배포 금지
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
