
[박찬 기자]
오픈AI의 'o1'과 비슷한 구조를 가진 모델들은 인간처럼 단계적 추론에 능숙하지만, '과잉 사고(overthinking)'라는 문제를 안고 있다. 이는 사소한 문제에 과도한 계산 자원을 소모하거나 불필요한 추론 과정을 반복, 비용을 쓸데없이 키우는 것을 말한다.
텐센트와 상하이 자오퉁대학교 연구진은 31일(현지시간) 추론 전문 모델의 과잉 사고 문제를 해결하기 위한 학습 방법을 온라인 아카이브에 게재했다. 논문 제목은 '2+3에 대해 많이 생각하지 마세요. o1 유사모델(o1-Like LLM)에 대한 과잉 사고에 관하여'다.
이에 따르면 과잉 사고는 계산 비용을 크게 증가시키지만, 결과의 정확성을 높이는 데 별다른 기여를 하지 않는 경우를 말한다. 예를 들어, '2+3'같은 간단한 문제를 헤결하는 데에도 o1과 비슷한 추론 전문 모델은 기존 대형언어모델(LLM)보다 훨씬 더 많은 토큰을 사용해 지나치게 세부적인 추론을 생성할 수 있다. 이는 모델의 실용성을 크게 떨어 뜨린다.
 |
(사진=셔터스톡) |
오픈AI의 'o1'과 비슷한 구조를 가진 모델들은 인간처럼 단계적 추론에 능숙하지만, '과잉 사고(overthinking)'라는 문제를 안고 있다. 이는 사소한 문제에 과도한 계산 자원을 소모하거나 불필요한 추론 과정을 반복, 비용을 쓸데없이 키우는 것을 말한다.
텐센트와 상하이 자오퉁대학교 연구진은 31일(현지시간) 추론 전문 모델의 과잉 사고 문제를 해결하기 위한 학습 방법을 온라인 아카이브에 게재했다. 논문 제목은 '2+3에 대해 많이 생각하지 마세요. o1 유사모델(o1-Like LLM)에 대한 과잉 사고에 관하여'다.
이에 따르면 과잉 사고는 계산 비용을 크게 증가시키지만, 결과의 정확성을 높이는 데 별다른 기여를 하지 않는 경우를 말한다. 예를 들어, '2+3'같은 간단한 문제를 헤결하는 데에도 o1과 비슷한 추론 전문 모델은 기존 대형언어모델(LLM)보다 훨씬 더 많은 토큰을 사용해 지나치게 세부적인 추론을 생성할 수 있다. 이는 모델의 실용성을 크게 떨어 뜨린다.
이 문제를 해결하기 위해 연구진은 모델 학습 과정에 '결과 효율성(outcome efficiency)'과 '과정 효율성(process efficiency)'이라는 두가지 평가 지표를 통합하는 자기 학습(self-training) 접근법을 제안했다.
이는 정확한 응답을 강조하는 동시에 모델의 반성적 사고(reflective reasoning) 능력을 유지해 불필요한 추론 과정을 줄이는 데 중점을 두는 방식이다. 또 'FCS(First-Correct Solutions)'와 'FCS+Reflection(FCS+반성)' 같은 전략을 도입, 계산 과정을 단순화하면서도 정확성을 유지할 수 있도록 했다.
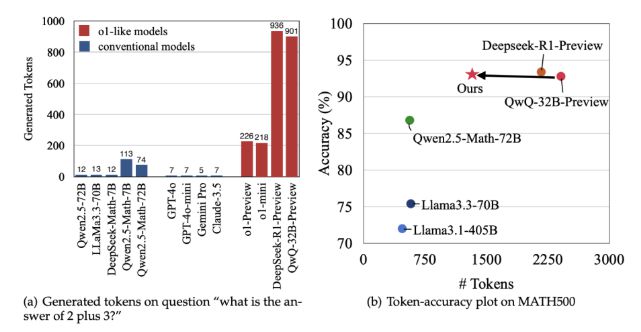 |
예를 들어, 알리바바의 o1 유사 모델인 'QwQ-32B-프리뷰'에 이 전략을 적용한 결과, MATH500 데이터셋을 해결하는 데 토큰 사용량을 48.6%나 줄이면서 정확도를 유지했다.
특히 FCS+반성 전략을 통해서 효율성은 최대 75.8%까지 향상됐다. GPQA와 AIME 같은 더 어려운 데이터셋에서도 계산 자원 사용량을 줄이면서 강력한 성능을 유지하는 데 성공했다고 전했다.
추론 모델의 비용 문제는 실제로 이를 도입하는 데 걸림돌로 작용하고 있다. 오픈Ai는 지난달 o1-프로를 출시하며, 이를 월 200달러짜리 요금제에서만 사용하도록 했다.
한편, 이처럼 추론 모델의 비용을 낮추려는 시도는 계속 등장하고 있다.
지난 주에는 난징대학교와 러트거스대학교, 매사추세츠대학교 애머스트 연구진이 토큰 예산 인식 LLM 추론 프레임워크인 'TALE(Token-Budget-Aware LLM rEasoning)'에 관한 논문을 발표했다.
TALE은 LLM이 사고 사슬(CoT) 방식으로 단계적 추론을 수행할 때 동적으로 토큰 예산을 추정하고 이를 프롬프트에 반영, 간결하면서도 정확한 응답을 생성하도록 유도한다.
특히 토큰 사용량을 최소화하면서 정확도를 유지할 수 있는 최적의 토큰 예산 범위를 식별하는 토큰 탄성(Token Elasticity) 개념이 핵심이다. 평균적으로 TALE은 토큰 사용량을 68.64% 절감하면서도 정확도 감소를 5% 미만으로 유지, 실용성과 효율성을 동시에 달성했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>