
'스텔라트레인' 프레임워크 개발
한국과학기술원(KAIST)은 한동수 전기전자공학부 교수 연구팀이 일반 소비자용 그래픽 처리 장치(GPU)를 활용해 네트워크 대역폭이 제한된 분산 환경에서도 AI 모델 학습을 수십에서 수백 배 가속할 수 있는 기술을 개발했다고 19일 밝혔다.
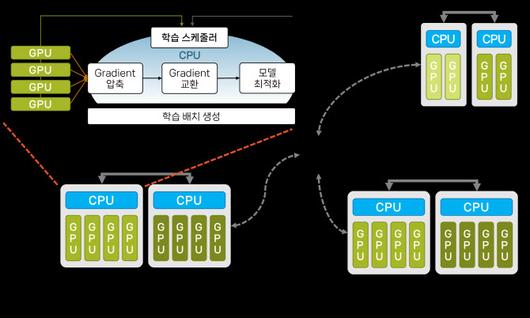 |
연구팀이 개발한 스텔라트레인 프레임워크.(자료=KAIST) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
기존에는 AI 모델을 학습하기 위해 개당 수천만원에 이르는 고성능 서버용 GPU(엔비디아 H100) 여러 대와 이들을 연결하기 위한 400Gbps급 고속 네트워크를 가진 고가 인프라가 필요했다. 하지만 소수의 거대 IT 기업을 제외한 기업과 연구자들은 비용 문제로 비싼 인프라를 도입하기 어려웠다.
연구팀은 이러한 문제를 해결하기 위해 ‘스텔라트레인(StellaTrain)’이라는 분산 학습 프레임워크를 개발했다. 이 기술은 고성능 H100에 비해 10~20배 저렴한 소비자용 GPU를 활용했다. 이를 통해 고속의 전용 네트워크 대신 대역폭이 수백에서 수천 배 낮은 일반 인터넷 환경에서도 효율적인 분산 학습을 가능하게 한다.
기존 저가 GPU를 사용하면 작은 GPU 메모리와 네트워크 속도 제한으로 인해 대규모 AI 모델 학습 시 속도가 수백 배 느려졌다. 연구팀이 개발한 스텔라트레인 기술은 CPU와 GPU를 병렬로 활용해 학습 속도를 높이고, 네트워크 속도에 맞춰 데이터를 효율적으로 압축·전송하는 알고리즘을 적용해 고속 네트워크 없이도 여러 대의 저가 GPU를 이용해 빠른 학습을 가능하게 했다.
특히, 학습을 작업 단계별로 CPU와 GPU가 나눠 병렬 처리할 수 있는 새로운 파이프라인 기술을 도입해 연산 자원의 효율을 극대화했다. 원거리 분산 환경에서도 GPU 연산 효율을 높이기 위해 AI 모델별 GPU 활용률을 실시간으로 모니터링해 모델이 학습하는 샘플의 개수를 동적으로 결정하고, 변화하는 네트워크 대역폭에 맞춰 GPU 간 데이터 전송을 효율화하는 기술을 개발했다.
연구 결과, 스텔라트레인 기술을 사용하면 기존 데이터 병렬 학습에 비해 최대 104배 빠른 성능을 낼 수 있는 것으로 나타났다.
한동수 교수는 “대규모 AI 모델 학습을 누구나 쉽게 접근하게 하는 데 기여하겠다”며 “앞으로도 저비용 환경에서도 대규모 AI 모델을 학습할 수 있는 기술 개발을 계속할 계획”이라고 말했다.
연구는 KAIST의 임휘준 박사, 예준철 박사과정 학생, UC 어바인의 산기타 압두 조시 교수가 수행했다. 연구 결과는 지난 달 호주 시드니에서 열린 ‘ACM SIGCOMM 2024’에서 발표됐다.
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
