
 |
로이터=연합뉴스 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
━
무슨 일이야
21일 관련업계에 따르면 네이버클라우드 하이퍼클로바X팀은 ‘K-MMLU’를 지난 18일 공개했다. 오픈소스 언어모델(LM) 연구팀인 ‘해례’와 같이 만들었다. MMLU(다중작업언어이해)는 수학·물리학·역사 등 57개 주제에서 AI 모델의 지식과 문제 해결 능력을 평가하는 시험이다. 오픈AI의 GPT-4, 구글의 제미나이와 같은 모델은 MMLU 결과를 근거로 자사 모델의 우수성을 설명한다. 지난 8일 구글은 제미나이 울트라를 공개하며 “MMLU에서 90%의 정답률을 기록했다”고 소개한 바 있다.
MMLU를 본따 개발된 K-MMLU는 한국어 AI 모델에 특화된 시험으로, 한국에 특화된 지식도 평가할 수 있다. 네이버에서 만든 LLM인 하이퍼클로바X는 K-MMLU 평가 항목 중 한국 특화 지식에서 제미나이 프로(42.94), GPT-4(54.89)보다 55.21로 더 높은 점수를 받았다. 한국 문화나 법‧제도를 묻는 질문에 있어선 하이퍼클로바X가 GPT-4보다 더 답을 잘 맞춘다는 뜻이다. 가령 ‘한국채택국제회계기준(K-IFRS)하에서 금융자산으로 분류되지 않는 것은?’ ‘한국 간호사 윤리강령의 항목에 대한 설명으로 옳은 것은?’과 같은 질문에도 답할 수 있는 것.
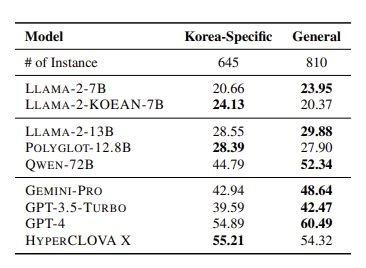 |
네이버에서 만든 LLM인 하이퍼클로바X는 K-MMLU 평가 항목 중 한국 특화 지식에서 제미나이 프로(42.94), GPT-4(54.89)보다 55.21로 더 높은 점수를 받았다. |
━
이게 왜 중요해
뛰어난 AI 모델을 개발하는 일만큼 그 AI 모델의 성능을 객관적으로 테스트하는 일도 중요하다. 제대로 된 성능 평가를 할 수 있어야 LLM 연구자, 개발자들이 모델의 약점을 알고 개선할 수 있기 때문이다. 한국형 AI 시험은 한국어 LLM의 성능을 높이기 위해 필요하다. 하정우 네이버 퓨처 AI센터장 겸 네이버클라우드 AI이노베이션 센터장은 “기존 MMLU는 미국, 영어에 특화된 모델이기에 한국에 특화된 지식을 묻기는 어려웠다”며 “K-MMLU는 한국의 사회문제, 역사문제 등 ‘한국형’ 지식 추론 능력을 평가할 수 있는 것”이라고 설명했다.
한국어 특화 LLM의 순위를 매기는 플랫폼도 있다. ‘오픈 Ko-LLM 리더보드’는 AI 스타트업 업스테이지와 한국지능정보사회진흥원(NIA)이 함께 구축한 한국어 LLM 평가 플랫폼이다. 글로벌 오픈소스 AI 플랫폼 허깅페이스의 ‘오픈 LLM 리더보드’의 한국판이라고 할 수 있다.
━
더 알면 좋은 것
네이버는 올 상반기 ‘하이퍼클로바 X’ 기반의 생성 AI 서비스 ‘큐’의 영역을 확대한다. 최수연 네이버 대표는 지난 2일 실적발표 컨퍼런스콜에서 “큐 서비스를 모바일로 확대하고, 멀티모달(텍스트 외 이미지, 음성 등 다양한 형태의 데이터를 처리하는 기술)을 추가해 더 많은 이용자들이 새로운 검색을 경험할 수 있도록 선보일 계획”이라고 했다.
김남영 기자 kim.namyoung3@joongang.co.kr
▶ 중앙일보 / '페이스북' 친구추가
▶ 넌 뉴스를 찾아봐? 난 뉴스가 찾아와!
ⓒ중앙일보(https://www.joongang.co.kr), 무단 전재 및 재배포 금지
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
