
 |
글로벌 AI 플랫폼인 허깅페이스는 AI 챗봇의 핵심 기술인 대규모언어모델(LLM)의 성능 시험 점수를 줄 세워 평가하는 '리더보드(순위표)'를 운영하고 있다. 사진 허깅페이스 홈페이지 캡처 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인공지능(AI) 모델의 성능 비교·평가 방식을 둘러싼 AI기업들의 고민이 깊어지고 있다. AI 모델 성능의 척도로 통했던 ‘리더보드(순위표)’가 실제 성능을 보장해주지 않는다는 불만이 쌓이면서다.
━
무슨 일이야
리더보드는 AI 모델 성능을 측정하는 시험인 ‘벤치마크(성능시험)’ 점수를 줄 세워 평가한 순위표다. 그간 국내 기업이 자사 AI 모델의 성능에 대해 “글로벌 1위”라고 발표했던 근거가 됐다. 글로벌 AI 플랫폼 허깅페이스가 운영하는 ‘오픈 LLM 리더보드’가 가장 널리 쓰인다. 지난 3월 국내 AI 기업 솔트룩스는 오픈 LLM 리더보드에서 글로벌 1위(매개변수 350억개 이하 모델 기준)를 기록했다고 밝혔다. AI 스타트업 업스테이지와 모레는 각각 지난해 말과, 올해 1월 같은 리더보드 전체 부문에서 글로벌 1위에 올랐다고 발표했다.
좋은 성과지만 최근 AI기업들 사이에선 리더보드 순위에 크게 의미부여를 하기 어렵다는 평가가 많이 나온다. 카카오뱅크 AI 개발부서 한 관계자는 “리더보드 상위권의 AI 모델을 사용해봐도, 각종 정성평가를 해보면 만족스럽지 않았다”고 말했다. 익명을 요청한 네이버 AI 관련 부서 관계자도 “해외를 중심으로 성능이 좋지 않은 소규모 LLM이 높은 순위를 기록하면서 리더보드의 신뢰성에 대한 업계의 의문이 꾸준히 늘었다”며 “모두가 신뢰할만한 거대언어모델(LLM) 평가 지표를 찾는 게 업계의 큰 과제”라고 말했다.
━
━
이게 왜 중요해
스탠퍼드대 인간 중심 AI 연구소(HAI)가 지난달 15일 발간한 보고서 ‘AI 인덱스 2024’에 따르면, 지난해 AI 모델의 기초가 되는 파운데이션모델은 149개가 출시됐다. 1년 전(72개)과 비교하면 두 배 이상 늘었다. 업계에선 이를 활용한 경량 모델, 버티컬 모델의 숫자는 훨씬 더 많았을것으로 추정하고 있다. AI모델 수가 기하급수적으로 늘다보니 이를 도입하려는 기업들 입장에선 어떤 모델이 더 적합하고 좋은지 비교해야하는 상황. 하지만 현재 리더보드 만으로는 어렵다는 평가다. 오픈AI의 GPT-4, 구글의 제미나이 등 빅테크의 LLM을 서비스에 도입한 뤼튼테크놀로지스의 박민준 AI 연구 수석은 “최근 수많은 종류의 AI 모델이 쏟아져 나오는 탓에, 이를 기술자가 일일이 직접 검사하기는 어렵다”며 “사전 검사를 통해 정량적 수치로 좋은 LLM을 찾아내는게 중요해졌다”고 말했다.
━
리더보드, 뭐가 문제야
리더보드에 대한 불신이 커진 건 소규모 LLM이 난립해서다. 특히 일부 해외 LLM 개발사의 경우 ‘편법’을 쓰기도 한다. LLM 성능을 개선하기 위해 다양한 자료를 학습시켜 성능을 개선하는 대신 시험(벤치마크) 고득점에 유리한 자료만 학습시킨다는 것. 예컨대, AI 모델의 상식 수준을 판단하는 벤치마크에 나올 시험 문제에 유리한 데이터만 집중 학습시키는 식이다. 기출문제만 달달 외우는 방식인 셈이다. 카카오뱅크의 AI 기술 개발부서 관계자는 “일부 리더보드에 높은 순위를 기록한 해외 LLM을 자세히 살펴보니 오염된 데이터를 사용한 사례도 많았다”고 말했다.
AI 모델의 특정 능력을 측정할 벤치마크가 없어서 리더보드에 반영하지 못하는 경우도 있다. 오픈AI의 최신 LLM인 GPT-4는 지난해 3월 발표됐는데, AI 모델의 한국어 능력을 가늠하는 벤치마크인 ‘해례 벤치’는 그로부터 두 달이 지난 5월에서야 시범 출시됐다. 네이버 관계자는 “지난해 오픈AI의 GPT-4의 한국어 능력을 가늠하기 위해 영어 능력 평가 시험인 MMLU를 임시로 번역해 측정에 사용했다”면서 “MMLU에 영어 문화권에만 통용되는 상식이 있었고, 번역 오류도 않았던 탓에 평가의 정확도가 낮아졌다”고 말했다.
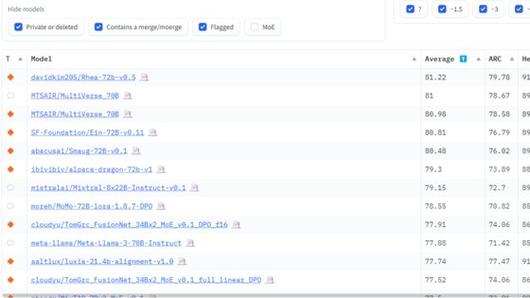 |
글로벌 AI 플랫폼인 허깅페이스는 AI 챗봇의 핵심 기술인 대규모언어모델(LLM)의 성능 시험 점수를 줄 세워 평가하는 '리더보드(순위표)'를 운영하고 있다. 사진 허깅페이스 홈페이지 캡처 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
━
━
해결책은
업계는 AI 모델 성능 비교를 위해 자체적으로 여러 가지 벤치마크 점수를 혼합해 성능을 가늠하거나, 정성평가를 병행하고 있다. 네이버는 자사의 LLM 하이퍼클로바X의 성능 평가에 한국어 능력 평가(3개), 영어 능력 평가(4개), 일반상식 평가(5개) 등 여러 종류 벤치마크 점수를 섞어서 사용한다. 독자적인 평가체계를 구축하는 곳도 있다. 뤼튼테크놀로지스 관계자는 “LLM을 도입한 AI 서비스가 이용자에게 원하는 답을 얼마나 빠르게 도출하는지 계산하고 평가에 반영한다”고 밝혔다.
━
앞으로는
AI 모델을 서로 비교하기 위한 업계의 고민은 계속될 전망이다. 업계에선 AI 모델이 윤리적인 답을 내놓는지 여부를 가늠하는 ‘AI 안정성’과 각 문화나 특정 국가에 통용되는 가치와 부합하는지 여부 등, 다양한 평가 요소가 등장할 것이라는 예측을 내놓는다. 박민준 뤼튼테크놀로지스 AI 연구 수석은 “하나의 제품인 카메라가 스마트폰에 장착되면 성능을 가늠할 중요한 구성요소가 되듯, 앞으로 생성AI도 특정 분야에서 얼마나 뛰어난 성능을 나타내는지가 중요한 평가 요소가 될 것”이라고 말했다.
윤상언 기자 youn.sangun@joongang.co.kr
▶ 중앙일보 / '페이스북' 친구추가
▶ 넌 뉴스를 찾아봐? 난 뉴스가 찾아와!
ⓒ중앙일보(https://www.joongang.co.kr), 무단 전재 및 재배포 금지
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
