
 |
젠슨 황 엔비디아 CEO가 GTC 2024에서 블랙웰 아키텍처를 소개했다 / 출처=엔비디아 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
가속 컴퓨터는 수많은 하드웨어 장치를 병렬로 연결해 처리 속도를 끌어올리는 방법이다. 이를 통해 컴퓨터의 물리적 한계가 크게 확장했고, 결과적으로는 기계 학습과 데이터 분석, 시뮬레이션 등 고차원적이고 대규모의 작업을 수행할 수 있게 됐다. AI 개발에 GPU가 쓰이는 이유도 GPU를 병렬로 연결해 대규모로 연산을 처리할 수 있어서다.
하지만 가속 컴퓨팅이 더 많은 분야에서 폭넓게 활용되며 엔비디아의 공급이 시장 수요를 충당하지 못하고, 이에 인텔과 AMD 모두 자체 가속기를 공개하며 지분 확대를 노리고 있다. 엔비디아의 대안을 자처하는 인텔과 AMD, 그리고 더 높은 성능으로 선두를 치고 나가는 엔비디아의 현재 상황을 짚어본다.
엔비디아, 블랙웰로 전력 사용량 줄이고 성능 상한 높인다
엔비디아가 2년 전 공개한 호퍼 아키텍처는 생성형 AI 시장의 엔진으로 작용하며 세상을 바꿨다. 하지만 GPU 자체가 AI 개발이 아닌 그래픽 처리 등 부동소수점 연산에 최적화된 반도체여서 성능은 높지만 전력 효율이 부족하다는 한계가 있다. 이를 인지한 엔비디아는 성능 상한을 높이면서도 전력 효율적인 방안을 제시해 단독 선두를 굳히려 한다. |
엔비디아 블랙웰 아키텍처 / 출처=엔비디아 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
엔비디아가 GTC 2024를 통해 소개한 블랙웰 아키텍처는 TSMC 4NP 공정으로 제조된 두 개의 다이로 구성되며, B200 AI 가속기로 제공될 시 총 2080억 개의 트랜지스터를 탑재한다. 각 칩 간 통신 속도는 초당 10TB에 달해 8비트 부동소수점 처리에서 호퍼 아키텍처 대비 2.5배, 추론으로는 다섯 배 높은 성능을 발휘한다. 또한 192GB 용량의 HBM3e 메모리를 배치해 H100 대비 30배까지 성능을 높였다.
블랙웰은 5세대 NV링크를 통해 초당 1.8TB로 장치 간 통신하며, 그레이스 CPU를 조합해 엔비디아 GB200 그레이스 블랙웰 슈퍼칩 형태로 제공된다. 총 8개의 B200이 탑재된 DGX B200 시스템은 총 1440GB의 GPU 메모리와 4TB 시스템 메모리를 탑재해 총 72 페타플롭스의 훈련 성능과 144페타플롭스의 추론 성능을 제공한다.
 |
72개의 B200 GPU가 탑재된 NVL72 시스템 / 출처=엔비디아 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
또한 전력 성능 개선에도 초점을 맞췄다. 기존 호퍼 GPU 아키텍처로 90일 안에 GPT-MoE-1.8T 모델을 훈련하려면 약 8000개의 GPU와 15메가와트의 전력이 필요했으나, 블랙웰 GPU는 2000개의 장치와 4메가와트로 처리해 전체 전력 사용량을 75%까지 줄일 수 있다. 72개의 GPU가 탑재되는 NVL72 규격으로 전 세대와 비교하면 AI 추론은 30배 빨라지고, 전력 대 성능비는 25배 높아진다.
AMD MI300X/A로 대응, ROCm 지원도 본격적
AMD 역시 지난해 12월 인스팅트 MI300A 및 MI300X 가속기를 출시하며 가속 컴퓨팅 시장에서의 몫을 늘리고 있다. MI300 시리즈는 304개의 CDNA3 아키텍처 기반의 GPU 컴퓨팅 유닛과 192GB HBM3 메모리, 초당 최대 5.3TB의 메모리 대역폭을 갖춰 이전 세대 MI250 대비 학습 능력이 최대 6.8배 향상됐다. 8개의 MI300X 플랫폼은 총 1.5TB의 HBM3 메모리와 최대 42.4TB의 메모리 대역폭을 갖춘다. |
AMD 인스팅트 MI300 시리즈 / 출처=AMD |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
2048개의 입력 토큰 및 128개의 출력 토큰을 활용한 Llama-70B 추론 테스트에서 MI300X는 엔비디아 H100와 비교해 vLLM 모델 FP16 결과에서 최대 2.1배 나은 성능을 보여주었다. AMD 인스팅트 MI300 시리즈는 델, 레노버 등 주요 하드웨어 기업에서 채용했고, 마이크로소프트와 오라클도 자사 클라우드에 MI300 시리즈 포함 계획을 발표했다.
한편 AMD가 넘어야 할 벽은 하드웨어가 아닌 소프트웨어에 있다. 엔비디아가 지금껏 시장을 선도해 온 배경은 십수년에 걸쳐 발전된 쿠다(CUDA) 기반의 개발 환경 덕분이다. 하지만 AMD는 2016년에 개발 환경인 ROCm을 만들고, 2023년 7월이 되어서야 윈도우를 지원하는 등 발전 속도가 느리다. 그나마 AMD가 뒤늦게 AI 가속기의 윈도우 지원을 발표하고, 전사적으로 AI 생태계 구성에 신경을 쓰면서 앞으로는 차츰 나아질 전망이다.
실제로 AMD의 2023년 4분기 데이터센터 부문 매출은 22억 8200만 달러(약 3조 1600억 원), 영업 이익은 6억 6600만 달러(약 9158억 원)를 기록했다. 이는 지난해 같은 기간 대비 38% 증가한 수치인데, AMD 인스팅트 GPU 및 4세대 AMD 에픽 CPU 등이 영향을 미쳤다. AMD AI 가속기 결과만 떼놓고 평가할 순 없지만, 조금씩 약진하는 모양새다.
인텔 가우디 3, 전방위적 대안으로 주목받는 중
 |
인텔 가우디 3 AI 가속기 주요 성능 요약 / 출처=인텔 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인텔은 지난 4월 9일 개최된 ‘인텔 비전’ 행사에서 가우디 2의 후속 제품인 가우디 3 AI 가속기를 선보였다. 가우디 3는 전 세대 대비 BF16(16비트 부동소수점) AI 컴퓨팅에서 4배, 메모리 대역폭에서 1.5배, 대규모 시스템 확장을 위한 네트워킹 대역폭이 2배 향상됐고, LLM 및 멀티모달 모델에서의 AI 추론 성능을 크게 끌어올렸다. 하드웨어는 64개의 AI용 텐서 프로세서 코어(TPC)와 8개의 행렬 곱셈 엔진(MME)으로 구성되며, 메모리는 128GB의 HBM2e으로 총 3.7TB의 메모리 대역폭을 갖는다.
성능 측면에서는 엔비디아 H100 대비 Llama 2-70B 및 130B, GPT-3 학습 시간을 50% 줄였고, Llama 2 700B 모델에서 50% 더 빠른 추론과 40% 향상된 추론 전력 효율성을 갖춘다. 인텔 측은 가우디 3가 H100보다 더 나은 성능과 합리적인 총 소유비용을 제공해 엔비디아 H100의 대안을 찾는 기업들이 관심을 끌 것으로 보고 있다.
엔비디아가 이기는 싸움이지만 ‘인텔 파운드리’는 변수
엔비디아는 올해 2분기 중 H200 GPU를 납품하며, 중순 이후에는 GH200 그레이스 호퍼 슈퍼칩까지 내놓는다. 라인업 상 2025년에는 블랙웰 기반의 B200 GPU와 GB200 그레이스 블랙웰 슈퍼칩까지 상용화한다. 인텔의 최신 AI 가속기인 가우디 3와 AMD MI300X가 이제 막 H100의 대안으로 제시되는 상황에서 몇 수 먼저 앞서 나가는 셈이다. 이 격차는 앞으로도 따라잡기 어려울 전망이다. |
인텔 오리건 주 D1X 반도체 공장에 배치된 ASML 하이-NA EUV 장비 / 출처=인텔 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
변수는 엔비디아와 AMD가 팹리스 기업인 반면, 인텔은 종합 반도체 기업이라는 점이다. 팹리스는 직접 반도체를 생산하지 않고 파운드리에 위탁하고, 종합 반도체 기업은 설계부터 생산까지 모두 직접 한다. 특히 인텔은 IDM 2.0 전략을 통해 파운드리 사업을 주류로 내세우고, 지난 4월 17일(현지 시각)에는 2025년 중 하이-NA EUV(고 개구수 극자외선 노광기)를 활용해 인텔 14A(옹스트롬, 약 1.4나노미터 상당) 공정 개발을 시작하겠다고 밝혔다.
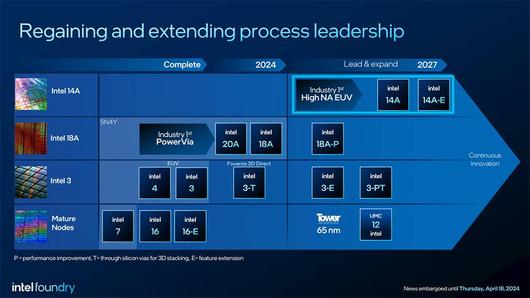 |
인텔은 올해 말까지 18A 공정에 돌입하고, 2027년에 14A 공정을 상용화한다 / 출처=인텔 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
하이 NA EUV를 활용하면 기존 EUV보다 1.7배 더 섬세하게 인쇄할 수 있고, 2D 확장을 통해 반도체 밀도를 2.9배까지 늘린다. 인텔은 렌즈 개구수가 0.33인 EUV와 0.55인 하이-NA EUV를 모두 사용할 예정이다. 반도체는 나노공정 단위가 첨예화할수록 생산 단가는 하락하고, 성능과 전력 효율은 향상된다. 인텔이 지금은 가우디 3등 주요 반도체를 TSMC에 위탁 생산하고 있지만, 향후 자사 AI 가속기에 최신 공정을 도입한다면 비약적인 성능 향상과 수요 공급의 유연성, 단가 맞춤 등을 앞세워 시장 분위기를 바꿀지도 모른다.
 |
엔비디아 GB200 그레이스 블랙웰 슈퍼칩 / 출처=엔비디아 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
물론 엔비디아 GPU를 활용하는 많은 기업들이 굳이 쿠다 생태계를 내려놓고, 인텔, AMD를 선택할 가능성은 낮다. 인텔과 AMD도 이 점을 인식해 경제성과 지속가능성, 수급의 안정 등을 장점으로 내세우며 경쟁한다. 앞으로도 이런 구도는 변함이 없겠지만, 엔비디아가 허점을 보인다면 언제든지 인텔과 AMD에게도 기회가 생길 수 있다. 특히 TSMC가 중국과 대만 분쟁이라는 지정학적 문제를 안고 있다는 점도 변수다.
가속 컴퓨팅 시장은 일반 사용자가 접할 분야는 아니다. 하지만 AI PC나 LLM을 비롯한 다양한 기술이 대중화할수록, AI 가속기를 비롯한 가속컴퓨팅 시장도 함께 발전한다. 또한 엔비디아 GPU의 높은 단가와 수급 안정성으로 인해 대안을 찾는 목소리도 계속 나오고 있다. 지금은 엔비디아가 시장의 단독 선두로 나서고 있지만, 장기적으로는 인텔과 AMD를 비롯한 수많은 기업들이 빈자리와 대안을 채우며 성장할 것이다.
글 / IT동아 남시현 (sh@itdonga.com)
사용자 중심의 IT 저널 - IT동아 (it.donga.com)
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
