
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
엔비디아의 영향력이 워낙 막강하다 보니 이를 대체하기 위한 반도체·하이퍼스케일 분야의 도전도 활발합니다. 신경망처리장치(NPU), xPU 등으로 불리는 AI가속기 주문형반도체(ASIC)를 범용 연산이 가능한 GPU(GPGPU) 대신 탑재하겠다고 했죠. 시장에서는 관련한 AI가속기 칩의 가능성에 높은 평가를 내리고 있지만, 개발자 등 현업에서는 현재까지 엔비디아를 대체할 만한 여력이 없다는 게 주된 평가입니다.
최근 활발하게 투자가 일어나는 딥러닝 모델 기반 AI는 크게 두 가지 분야로 나뉩니다. 학습(Training) 및 모델 구축, 그리고 추론(Inference)이죠. 학습은 거대한 데이터 내 일종의 규칙을 찾아 파운데이션 모델을 구축하는 분야입니다. 문장 등을 입력하면 이와 관련한 출력값을 내놓는 초거대언어모델(LLM)이 이 분야에 해당하죠. 엔비디아의 GPGPU가 활발하게 탑재되는 곳도 바로 학습용 데이터센터입니다.
엔비디아의 경쟁력은 높은 GPGPU의 범용적 성능과 유연한 개발 생태계입니다. 생성형AI가 부각되기 한참 전부터 관련 개발을 지속해 왔고, 지난해 오픈AI의 'GPT3'가 성공적으로 안착하면서 꽃피우기 시작했죠.
GPU는 직렬로 부동소수점 등을 연산하는 CPU와 달리 병렬 연산을 진행합니다. 이 덕에 게임 더링 등 그래픽 작업에 특화됐습니다. 마찬가지로 딥러닝 학습을 진행하려면 대규모의 데이터를 처리해야 하는데, 이를 하나씩 처리하기보다는 여러 개를 동시에 연산하는 것이 더 유리합니다.
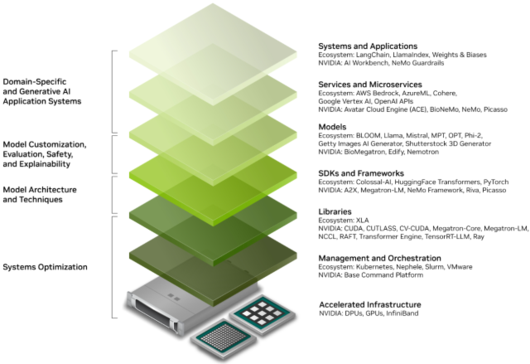 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
개발자가 중심이 되는 AI 분야에서, 모든 개발을 진행할 수 있도록 한 소프트웨어 스택의 역할은 무엇보다 중요합니다. 각 회사가 목표하는 AI 모델 개발은 물론, 편의성을 높여 개발 속도를 가속화할 수 있다는 이유때문입니다. 엔비디아는 이를 시장 초기부터 고려해 왔고, 자체 GPU 제품과 연계해 생태계를 구축했습니다. 엔비디아의 생태계 장악력이 비약적으로 강해질 수밖에 없는 이유죠.
혹자는 엔비디아의 AI칩 생태계의 중요성을 구글 검색을 통해 비유하기도 합니다. 한 업계 관계자는 "엔비디아의 칩을 사용하다 오류가 났을 때, 이때 나온 오류 메시지를 구글에다 검색해보면 그 이유를 설명하는 내용이 주르륵 나온다"며 "반면 다른 AI칩 회사들의 오류 메시지를 구글에 검색해도 그 결과가 나오지 않는다. 이것이 개발자 입장에서 말하는 생태계"라고 설명했습니다.
이는 반도체 팹리스나 빅테크가 추론용 AI가속기 개발에 집중하는 추세와 맞물립니다. 학습 분야에서는 엔비디아 생태계를 뚫고 진입하기가 어렵다 보니, 아직 초기 단계인 추론 시장에 진입하겠다는 의미입니다.
물론 추론 분야 역시도 엔비디아가 두각을 드러낼 가능성이 높습니다. 이미 엔비디아는 고성능에 범용성이 높은 칩과 PCIe와 별도로 운용되는 하드웨어인 엔브이링크(NVLink), 트리톤(Triton) 추론 서버 등 API 영역에서 꾸준히 자체 생태계를 확장하고 있죠. 초기 시장을 선점하면 그 토대가 이어지는 관성의 힘, 선두주자의 진입장벽도 무시할 수 없습니다.
그렇다고 신규 진입자에게 어려움만 있는 것은 아닙니다. 엔비디아의 AI 카드·서버 가격이 막대한 데다, 이를 활용하기 위한 전력 인프라 구축·유지비용이 매우 높은 축에 속한 탓입니다.
반면 추론용 서버는 학습·모델 구축용 서버와 비교해 처리해야 할 데이터이 적습니다. 일부 서비스에 특화된 덕이죠. 따라서 GPGPU만큼의 고성능이나 범용성을 가질 필요가 없으며, 전성비(전력 대비 성능)가 높은 제품이 경쟁력을 가지고 있습니다.
추론용 분야의 개발 진영은 데이터센터·하이퍼스케일러와 팹리스입니다. 데이터센터가 자체 AI서버에 탑재할 커스텀 칩을 설계하고 있고, 팹리스 업체가 범용적이거나 데이터센터 고객사에 특화된 칩을 개발 중이죠. 구글·아마존웹서비스(AWS)·마이크로소프트(MS)·메타 등이 데이터센터 진영에 해당합니다. 인텔·AMD 등 글로벌 빅테크와 그록(Groq)·텐스토렌트·세라브라스·사피온·리벨리온 등 스타트업 팹리스가 후자로 볼 수 있습니다.
두 진영에서 나올 칩은 서로 상호보완적인 역할을 할 것으로 보입니다. 데이터센터의 커스텀 칩은 자체 AI 서비스의 핵심 기능을 담당하고, 그 이외 분야를 팹리스의 칩이 담당하는 구조로 예상됩니다.
이들이 시장 진입을 위해 해결해야 할 과제는 단연 생태계 구축입니다. 칩 자체의 하드웨어 성능보다도 개발자들의 편의성을 높이는 소프트웨어 인프라, 접근성 등이 중요한 시점이죠. 이미 각 팹리스 자사 칩의 개발 도구를 파이토치·텐서플로우 등 주요 ML API와 호환하려는 노력이 이어지고 있습니다.
일각에서는 AI 개발을 위한 소프트웨어 스택을 비(非)엔비디아 진영에서 함께 구축해야 한다는 지적도 있습니다. 각 기업이 자사의 소프트웨어 인프라만 강조한다면 오히려 영향력이 감소할 수 있다는 이유에서죠. 이러한 공동 인프라 구축의 조타를 누가 잡을지도 관심 있게 지켜봐야 할 대목입니다.
- Copyright ⓒ 디지털데일리. 무단전재 및 재배포 금지 -
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
