
[박찬 기자]
소형언어모델(sLM)로 유명한 리퀴드 AI가 지금까지 공개한 모델 중 가장 강력한 엣지 AI용 모델을 출시했다.
리퀴드 AI는 5일(현지시간) 온디바이스 및 엣지 환경에 최적화된 차세대 소형 파운데이션 모델 'LFM2.5'를 공개했다.
LFM2.5는 기존 LFM2 아키텍처를 기반으로 성능과 학습 규모를 대폭 확장한 모델 군으로, 오픈 웨이트 형태로 허깅페이스에 공개됐으며 리퀴드 AI의 LEAP 플랫폼을 통해서도 제공된다.
 |
소형언어모델(sLM)로 유명한 리퀴드 AI가 지금까지 공개한 모델 중 가장 강력한 엣지 AI용 모델을 출시했다.
리퀴드 AI는 5일(현지시간) 온디바이스 및 엣지 환경에 최적화된 차세대 소형 파운데이션 모델 'LFM2.5'를 공개했다.
LFM2.5는 기존 LFM2 아키텍처를 기반으로 성능과 학습 규모를 대폭 확장한 모델 군으로, 오픈 웨이트 형태로 허깅페이스에 공개됐으며 리퀴드 AI의 LEAP 플랫폼을 통해서도 제공된다.
CPU와 NPU 환경에서 빠르고 메모리 효율적인 추론을 목표로 설계된 하이브리드 아키텍처를 유지하면서, 사전 학습 데이터와 사후 학습 파이프라인을 크게 확장했다.
사전 학습 데이터는 기존 10조 토큰에서 28조 토큰으로 늘어났고, 강화 학습(RL)을 중심으로 한 사후 훈련 파이프라인을 대규모로 확장해 10억(1B) 매개변수급 모델의 성능 한계를 끌어올렸다.
단일 모델이 아니라, 기본 언어 모델 'LFM2.5-1.2B-베이스' 지시 특화 언어 모델 'LFM2.5-1.2B-인스트럭트' 일본어 특화 모델 'LFM2.5-1.2B-JP' 비전-언어 모델 'LFM2.5-VL-1.6B' 오디오-언어 모델 'LFM2.5-오디오-1.5B' 등이 출시됐다.
LFM2.5-1.2B-베이스와 LFM2.5-1.2B-인스트럭트는 개발자들이 활용 시나리오에 맞는 솔루션을 효과적으로 구축할 수 있도록 제공된다.
LFM2.5-1.2B-베이스는 모든 LFM2.5-1.2B 계열 모델의 출발점이 되는 사전 학습 체크포인트다. 대규모 미세조정이 필요한 작업에 적합하며, 특정 언어나 도메인에 특화된 어시스턴트 구축, 기업 내부의 독점 데이터 학습, 새로운 사후 훈련 기법 실험 등 고급 커스터마이징 용도에 활용하는 것이 권장된다.
LFM2.5-1.2B-인스트럭트는 대부분의 일반적인 활용 사례를 겨냥한 범용 지시 특화 모델이다. 지도 미세조정(SFT), 선호도 정렬, 대규모 다단계 RL을 거쳤으며, 추가 설정 없이도 뛰어난 지시 수행 능력과 도구 활용 능력을 제공하는 것이 특징이다.
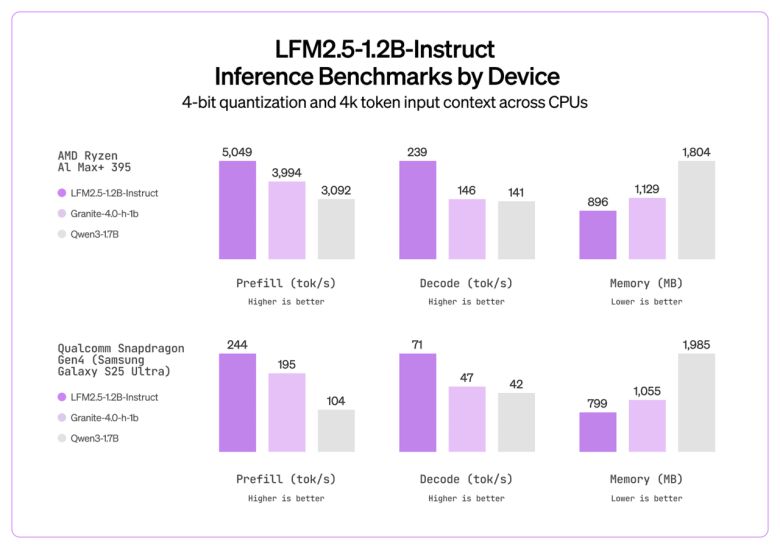
LFM2.5-1.2B-인스트럭트는 GPQA, MMLU 프로, IF이밸, IF벤치 등 주요 벤치마크에서 경쟁 모델에 비해 뛰어난 성능을 기록했다.
GPQA에서는 38.89점, MMLU Pro에서는 44.35점을 기록해, 같은 1B급 오픈 모델인 '라마-3.2-1B 인스트럭트'나 '젬마-3-1B IT'를 크게 앞섰다. 다단계 지시 수행과 함수 호출 능력을 평가하는 IF이밸과 IF벤치에서도 각각 86.23점, 47.33점을 기록하며, 1B급 모델 중 가장 높은 성능을 보였다.
 |
LFM2.5-1.2B-JP는 일본어에 최적화된 텍스트 모델로, JMMLU와 일본어 M-IF이밸, 일본어 GSM8K 등에서 범용 모델에 비해 성능이 뛰어났다. '큐원3-1.7B'나 라마 3.2-1B 인스트럭트, 젬마 3-1B IT 등 소형 다국어 모델과 경쟁하거나 이를 능가하는 성과를 냈다.
비전-언어 모델인 LFM2.5-VL-1.6B는 LFM2.5-베이스 백본을 기반으로 재설계된 최신 비전-언어 모델이다. 실제 환경에서의 활용 성능을 강화하는 데 초점을 맞췄으며, 특히 다중 이미지 이해 능력에서 뚜렷한 개선을 이뤘다.
또 아랍어, 중국어, 프랑스어, 독일어, 일본어, 한국어, 스페인어 등 다양한 언어의 시각적 프롬프트를 정확하게 처리, 다국어 비전 이해 성능을 향상했다. MM스타, OCR벤치 v2, MMMU, 다국어 MM벤치 등 다양한 시각적 추론과 OCR 벤치마크에서 이전 세대 모델인 LFM2-VL-1.6B에 비해 전반적인 성능 향상을 달성했다.
이 모델은 문서 이해, 사용자 인터페이스 판독, 다중 이미지 추론 등 엣지 환경의 실제 활용 시나리오가 주요 타깃이다.
LFM2.5-오디오-1.5B는 음성과 텍스트를 모두 입력·출력으로 지원하는 네이티브 오디오-언어 모델이다. 음성 인식(ASR), 언어 모델 처리, 음성 합성(TTS)을 단계적으로 연결하는 기존 파이프라인 방식과 달리, 오디오를 하나의 모델에서 직접 처리함으로써 구성 요소 간 정보 손실을 없애고 종단 간 지연 시간을 크게 줄였다.
특히 모바일 CPU 기준 동일한 정밀도에서 기존 LFM2의 Mimi 디토크나이저보다 8배 빠른 오디오 디토크나이저를 적용해, 제한된 하드웨어 환경에서도 효율적인 음성 처리를 가능하게 했다. 디토크나이저는 언어 모델 백본이 생성한 이산 토큰을 고품질 오디오 파형으로 변환한다.
이 모델은 실시간 음성 대화를 위한 인터리브드(interleaved) 생성 모드와 음성 인식·음성 합성에 적합한 시퀀셜(sequential) 생성 모드를 지원한다. 또 INT4 정밀도의 양자화 인지 학습(QAT)을 적용해 저정밀 환경에서도 FP32 기반 기존 모델과 비교해 품질 저하를 최소화하며, 엣지 디바이스에 직접 배포할 수 있도록 설계됐다.
리퀴드 AI는 "이번 모델 군의 출시는 엣지 환경에서 안정적인 에이전트를 개발하는 데 있어 상당한 도약을 의미한다"라며 "앞으로는 모델 크기와 추론 기능을 확장해 나갈 예정"이라고 밝혔다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>