
[박찬 기자]
현재 대형언어모델(LLM)의 주류를 이루는 자기회귀적(autoregressive) 트랜스포머 아키텍처의 대안으로, 확산(diffusion) 기반 LLM이 주목받고 있다. 특히, 코드 생성처럼 순차적인 전개보다 전체 구조의 조율과 반복적 수정이 중요한 작업에서는 확산 LLM(dLLM)이 강력한 가능성을 보여준다.
애플은 홍콩대학교 연구진과 16일(현지시간) 1300억개의 코드 토큰으로 학습한 70억 매개변수의 dLLM '디퓨코더(DiffuCoder)'에 관한 논문을 아카이브에 게재했다. 모델은 깃허브에서 오픈 소스로 다운로드할 수 있다.
디퓨코더는 기존 트랜스포머 구조와는 달리, 토큰을 하나씩 순서대로 만들지 않고 문장 전체를 한꺼번에 조금씩 다듬어가는 '마스크드 디퓨전(Masked Diffusion)' 방식으로 작동한다.
 |
(사진=셔터스톡) |
현재 대형언어모델(LLM)의 주류를 이루는 자기회귀적(autoregressive) 트랜스포머 아키텍처의 대안으로, 확산(diffusion) 기반 LLM이 주목받고 있다. 특히, 코드 생성처럼 순차적인 전개보다 전체 구조의 조율과 반복적 수정이 중요한 작업에서는 확산 LLM(dLLM)이 강력한 가능성을 보여준다.
애플은 홍콩대학교 연구진과 16일(현지시간) 1300억개의 코드 토큰으로 학습한 70억 매개변수의 dLLM '디퓨코더(DiffuCoder)'에 관한 논문을 아카이브에 게재했다. 모델은 깃허브에서 오픈 소스로 다운로드할 수 있다.
디퓨코더는 기존 트랜스포머 구조와는 달리, 토큰을 하나씩 순서대로 만들지 않고 문장 전체를 한꺼번에 조금씩 다듬어가는 '마스크드 디퓨전(Masked Diffusion)' 방식으로 작동한다.
또 이미지처럼 연속적인 노이즈를 추가하는 대신, 토큰 시퀀스에서 무작위로 토큰을 마스크하고 모델이 원래의 토큰을 예측하도록 학습한다. 이를 통해 토큰을 반드시 왼쪽부터 오른쪽 순으로 생성할 필요 없이, 더 자유롭게 만들 수 있다.
이 방식은 확산 과정처럼 거친 덩어리에서 세밀한 부분으로 텍스트를 가다듬는 식으로, 모델은 먼저 많은 부분이 마스크된 텍스트로 시작해 이를 점차 정제해 일관된 출력을 생성한다. 이 방식은 dLLM이 매 단계에서 전체 맥락을 동시에 고려할 수 있게 해주는 장점이 있다.
또 샘플링 온도(Temperature)를 높이면, 어떤 단어를 고를지뿐만 아니라 어떤 순서로 만들지까지 가능해진다는 사실도 밝혀냈다. 이런 다양성 덕분에 강화 학습(RL)에서는 더 많은 경우를 실험해볼 수 있어 학습에 도움이 된다.
샘플링 온도는 다음에 나올 토큰을 얼마나 다양하게 고를지 조절하는 값이다. 온도가 0이면 가장 확률이 높은 토큰만 선택되고, 값이 커지면 덜 확실한 토큰도 선택될 수 있어 결과가 더 다양해진다.
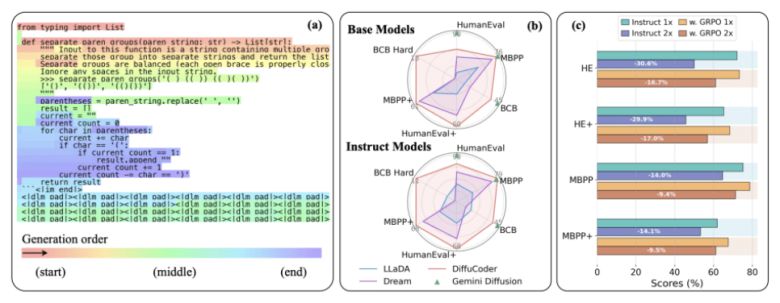 |
이에 앞서 등장한 '라다(LLaDA)'나 '머큐리(Mercury)'와 같은 dLLM도 속도와 처리량 면에서 자기회귀 모델을 능가하는 모습을 보여 줬다. 하지만 이런 장점에도 불구하고, dLLM은 추론 능력 면에서 자기회귀 모델보다 뒤져 있었다는 지적이다.
이 문제를 해결하기 위해 RL이 중요한 역할을 한다. 모델이 올바른 추론 단계를 수행하거나 최종 답을 도출할 때마다 보상을 주는 방식으로 RL을 적용, 언어 모델의 지시 따르기 및 추론 능력을 향상할 수 있다는 설명이다.
연구진은 RL을 강화하기 위해 '커플드-GRPO(coupled-GRPO)'라는 새로운 샘플링 방법을 만들었다. 이는 서로 잘 어울리는 마스크 노이즈를 활용해 문장을 완성하는 중간 데이터를 만들고, 학습 과정에서 발생하는 불안정한 요소를 줄여 효율을 높인다.
실험 결과, 이 방법은 기존보다 더 안정적으로 보상을 학습할 수 있었다. 코드 생성 성능도 '이밸플러스(EvalPlus)' 기준 4.4% 향상됐다.
이를 통해 디퓨코더는 왼쪽에서 오른쪽으로만 생성하는 기존 방식의 영향을 덜 받게 됐고, 한번에 여러 부분을 동시에 생성하는 능력도 더 좋아졌다는 설명이다.
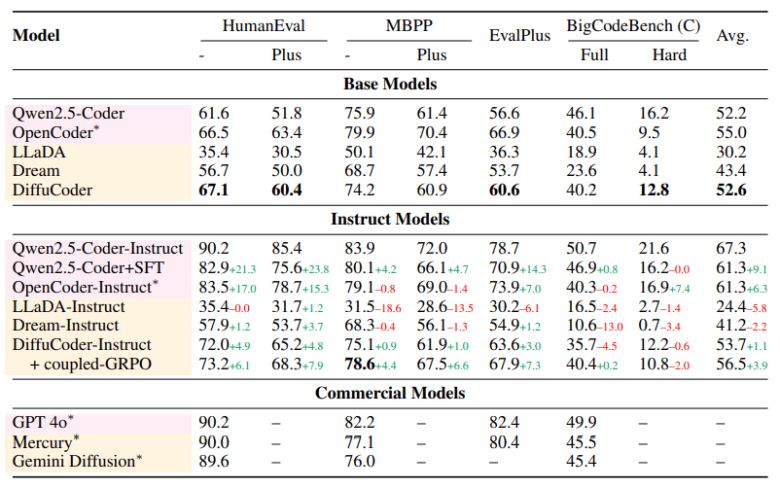 |
디퓨코더의 학습은 '큐원-2.5-코더(Qwen-2.5-Coder)'를 기반으로, 리파인코드(RefineCode)와 스택v2(Stackv2)의 대규모 코드 데이터셋을 활용한 4단계 전이 학습 절차로 이루어졌다.
평가에는 휴먼이밸(HumanEval), MBPP, 이밸플러스, 빅코드벤치(BigCodeBench) 등의 주요 코드 벤치마크가 사용됐다. 디퓨코드는 베이스 모델인 큐원-2.5-코더와 오픈 소스 '오픈코더(OpenCoder)'는 물론, 'GPT-4o' 등 사용화 모델까지 대부분 자동회귀 기반 모델과 유사한 성능을 보였다.
특히, 커플드-GRPO를 이용한 RL 이후, 모델의 최적 샘플링 온도가 기존 0.2에서 1.2로 증가했다. 이는 모델이 토큰 생성을 더 정밀하게 조정할 수 있게 됐다는 것을 말한다.
이처럼 최근 dLLM 출시가 빠르게 확대되고 있다.
스타트업 인셉션은 지난 3월 '머큐리'라는 최초의 상업적 규모의 dLLM을 출시했고, 이어 4월에는 메타가 dLLM의 추론 성능을 개선할 수 있는 RL 프레임워크 'd1'을 공개했다. 또 5월 I/O에서는 구글이 실험적 dLLM '제미나이 디퓨전'을 출시했다.
이제는 LLM 분야에서 뒤처진 것으로 알려진 애플까지 이런 흐름에 동참한 셈이다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>