
[박우용 편집위원] [디지털포스트(PC사랑)=박우용 편집위원 ]
AI는 점점 더 똑똑해지고 있다. 그런데 지금 관련 산업이 겪는 어려움은 단순히 '똑똑한 AI'의 문제가 아니다. 그 AI를 어디서, 얼마나 효율적으로 돌릴 수 있느냐에 달렸다. 모델 경쟁은 계속되지만, 그것만으로는 부족하다.
GPT-4, Gemini, Claude, LLaMA 등 대형 언어 모델은 계속해서 더 커지고 있다. 성능도 상향 평준화되고 있다. 동시에, 작고 가볍고 빠르게 동작하는 경량화된 AI 모델들도 빠르게 증가하는 중이다. 대규모 모델은 데이터센터에서 훈련되고, 소형화된 모델은 스마트폰, 차량, 산업기기 등에서 실시간 실행된다. AI는 '확장(Scaling up)'과 '최적화(Optimization)'라는 두 방향으로 진화하고 있다. 하지만 이 두 방향 모두 동일한 질문에 직면한다.
AI는 점점 더 똑똑해지고 있다. 그런데 지금 관련 산업이 겪는 어려움은 단순히 '똑똑한 AI'의 문제가 아니다. 그 AI를 어디서, 얼마나 효율적으로 돌릴 수 있느냐에 달렸다. 모델 경쟁은 계속되지만, 그것만으로는 부족하다.
GPT-4, Gemini, Claude, LLaMA 등 대형 언어 모델은 계속해서 더 커지고 있다. 성능도 상향 평준화되고 있다. 동시에, 작고 가볍고 빠르게 동작하는 경량화된 AI 모델들도 빠르게 증가하는 중이다. 대규모 모델은 데이터센터에서 훈련되고, 소형화된 모델은 스마트폰, 차량, 산업기기 등에서 실시간 실행된다. AI는 '확장(Scaling up)'과 '최적화(Optimization)'라는 두 방향으로 진화하고 있다. 하지만 이 두 방향 모두 동일한 질문에 직면한다.
"이 모델을 실제 환경에서 어떻게 실행할까." AI 기술의 진정한 진화는 모델의 구조나 성능만으로 평가되지 않는다. 어떤 하드웨어와 시스템, 생태계 위에서 효율적으로 동작하느냐가 핵심 평가 기준이 된다. 실행 환경과 최적화 능력은 AI의 산업적 가치와 혁신 가능성을 좌우하는 가장 중요한 요소다.
AI의 미래는 모델 자체의 똑똑함이 아니라, 실제로 모델이 실행되는 인프라와 생태계의 설계에 달려 있다.
시스템 설계 출발점, 전략성 강화되는 AI 칩
AI 칩은 더 이상 단순한 고성능 계산기가 아니다. 병렬 연산, 고대역폭 메모리, 전용 가속기, 저전력 설계 등 다양한 요구가 반영된다. 각 기업은 자신이 겨냥한 AI 환경에 따라 칩을 전략적으로 방향성을 더욱 명확히 드러내고 있다.
NVIDIA는 자사 GPU 아키텍처 'Blackwell'을 바탕으로 대규모 AI 학습과 추론 모두를 단일 아키텍처에서 처리할 수 있는 구조를 제시했다. 특히 Grace Blackwell 슈퍼칩은 고대역폭 인터커넥트, 다층 메모리 통합, AI 최적화된 병렬 처리 구조를 강조하며, 초거대 AI 모델을 실행하는 데이터센터 인프라의 핵심으로 자리매김하고 있다. 기존 Hopper 대비 트랜지스터 밀도는 2배 이상 증가했으며, 메모리 대역폭과 FP8 연산 성능은 최대 10배까지 향상됐다는 발표는, NVIDIA가 단순히 고성능 칩을 넘어 전체 AI 시스템의 수직 통합과 플랫폼화를 전략적으로 강화하고 있음을 보여준다.
 |
엔비디아 AI 칩 \'블랙웰\' (사진=엔비디아) |
AMD는 최신 Instinct MI300X를 통해 GPU 기반 추론 성능을 강화하고, CPU·GPU 통합 구조(GPGPU)를 확장했다. MI300X는 HBM3 메모리 탑재와 더불어, 프로그래머 친화적 오픈 아키텍처(ROCm)를 통해 AI와 HPC(High Performance Computing) 개발자 모두를 끌어들이는 전략을 취한다. AMD는 AI 연산뿐 아니라, 범용 고성능 연산 통합 플랫폼으로서의 확장성을 전면에 내세우고 있다.
Intel은 AI 가속기 라인업인 Gaudi 3를 통해 고성능 대비 저비용 AI 인프라 구축을 강조하고 있다. 또한 CPU(Granite Rapids), GPU(Falcon Shores), NPU(앞으로의 Lunar Lake 통합) 등을 통해 모듈화된 AI 연산 생태계를 목표로 삼고 있으며, 파운드리 사업과의 연계를 통해 AI 칩 설계부터 생산까지 수평적 확장 전략을 강화하고 있다.
ARM은 Arm Neoverse Compute Subsystems (CSS)를 중심으로 엣지부터 클라우드까지 동일한 ISA(Instruction Set Architecture) 기반의 확장 가능한 AI 연산 플랫폼을 구축하고 있다. 특히 NPU 통합과 함께 AI 프레임워크 연동 최적화를 강화한 KleidiAI를 통해, 모바일·IoT·클라우드 간 이질적 연산 자원의 통합 운용을 지향한다. ARM의 목표는 초저전력 AI 실행 환경의 표준화다.
Qualcomm은 Snapdragon X 시리즈를 통해 PC 시장으로 확장하면서, AI 전용 NPU와 CPU·GPU를 통합한 온디바이스 대형 모델 실행 환경을 제시했다. 특히 45TOPS 수준의 NPU 성능은 생성형 AI 모델의 모바일 및 랩톱 단에서 실시간 실행을 가능케 하며, 배터리 효율성과 지연 시간 최소화 중심의 AI 사용자 경험 혁신을 강조하고 있다.
Apple은 M4 칩 발표를 통해, 실제 사용자 경험을 중심으로 설계된 온디바이스 AI 시스템의 정점을 보여주고 있다. Neural Engine은 Apple 발표에 따르면 M3 대비 60% 이상 향상된 성능을 기록했고, 초당 38TOPS(Trillion Operations Per Second)의 연산 능력을 제공한다. 이러한 개선은 Siri, 음성 명령, 실시간 UI 조작, 이미지 분석 등에서 더욱 즉각적이고 자연스러운 사용자 경험을 가능하게 한다. Apple은 철저하게 AI 모델보다는 실행 환경과 인터페이스의 일체화를 통해 차별화를 강화하고 있다.
결국, 각 기업은 단순한 연산 속도 경쟁을 넘어, 어디서 실행할 것인지(데이터센터·엣지), 어떻게 연결할 것인지(이기종 연산 자원 간 통합), 그리고 누구나 개발하고 적용할 수 있는가(생태계 접근성)에 초점을 맞추고 있다. 결국 AI 칩 설계는 더 이상 성능 스펙의 나열이 아니라, 전략적 플랫폼 기획과 산업별 투입 가능성을 반영한 종합 설계로 진화하고 있다.
 |
인공지능(AI) 이미지 사진=ARM |
인터커넥트가 AI 시스템 성능 좌우한다
AI 연산은 이제 하나의 칩 안에서 끝나지 않는다. CPU, GPU, NPU, 메모리 등이 복수로 결합되고, 이들이 병렬적으로 작동하는 다중 컴포넌트 구조가 표준이 됐다. 문제는 단순한 연산 능력이 아니라, 이질적인 연산 자원들 사이의 연결 효율이다. 실제 AI 시스템의 성능은 개별 칩의 속도보다, 그 칩들이 얼마나 긴밀하고 신속하게 연결되는지에 달려있다.
NVIDIA는 NVLink-C2C 인터커넥트 기술을 통해 Grace Hopper 슈퍼칩 내부에서 CPU와 GPU를 직접 연결하는 구조를 제시했다. 이는 데이터 이동 병목을 최소화하고, AI 학습과 추론을 위한 일관된 메모리 공유를 가능하게 한다. 특히 NVSwitch와 NVLink-Fusion으로 확장 가능한 네트워크 구조는, AI 슈퍼컴퓨터 수준의 시스템 플랫폼 기업으로 진화하고 있음을 보여준다.
AMD는 CPU와 GPU 간의 고효율 연결 구조를 중심으로, 물리적 인터커넥트 최소화와 메모리 대역폭 극대화를 동시에 달성하는 패키징 설계를 고도화하고 있다. MI300 시리즈는 CPU-GPU 통합 패키지를 통해 연산 자원 간 거리를 최소화하고, 고속 인터페이스를 통한 데이터 이동 경로를 최적화함으로써, 복잡한 AI 워크로드에서 병목 없이 연산이 흐를 수 있는 구조적 기반을 마련한다. ROCm 생태계와의 통합은 이러한 하드웨어 구조 위에 소프트웨어 최적화를 더해, 서버급 AI 인프라에서 연산 밀도와 전력 효율의 균형을 구현하는 AMD의 전략을 구체화한다.
 |
인텔의 AI 엣지 시스템. 사진=인텔 |
Intel은 다양한 연산 자원을 모듈형 블록으로 구성하고, 이들 간의 인터커넥트를 효율적으로 조율할 수 있는 구조를 통해 시스템 전체의 확장성과 유연성을 확보한다. CPU, GPU, NPU, Gaudi3 가속기 등 이질적인 연산 장치는 통합 가능한 소프트웨어 계층인 OneAPI를 통해 상호 연결되며, 이를 통해 각 컴포넌트 간 데이터 이동 경로를 최소화하고 연산 자원의 분산 할당이 가능하도록 한다. Intel의 전략은 단일 하드웨어 성능 극대화보다, 복수의 연산 자원이 유기적으로 연계된 인터커넥트 구조 위에서 전체 시스템 효율을 극대화하는 데에 중점을 둔다.
ARM은 SoC 내부에 CPU, GPU, NPU를 고밀도로 통합하고, 각 컴포넌트 간의 초저전력 인터커넥션 구조를 설계함으로써, 연산 자원 간의 데이터 이동을 최소화하고 실시간 처리를 가능하게 한다. 이러한 구조는 모바일 및 IoT 기기처럼 에너지 제약이 큰 환경에서도 AI 연산의 지속성과 민첩성을 확보하게 하며, KleidiAI는 이러한 인터커넥션 위에서 프레임워크와 하드웨어 간의 경계를 최소화하는 방향으로 인터페이스를 최적화한다. 결국 ARM의 인터커넥트 전략은 경량 연산 환경에서의 성능과 효율을 동시에 충족시키는 구조적 기반을 제공한다.
Qualcomm은 Hexagon NPU 아키텍처를 바탕으로 연산 가속기 내부에 분산형 메모리와 데이터 흐름 엔진을 결합하여, AI 처리를 내부적으로 단기 경로에서 완결시킬 수 있는 구조를 강조하고 있다. 이를 통해 전력 소모를 줄이고, 모바일 환경에서 대형 모델도 로컬에서 실시간 실행할 수 있도록 한다.
Apple은 M 시리즈 SoC 내에서 CPU, GPU, NPU, ISP 등을 단일 실리콘 상에 유기적으로 연결하며, 고속 인터커넥트 구조를 통해 운영체제 수준에서 연산 자원을 동적으로 분산 처리한다. 이 덕분에 사용자는 디바이스 성능 한계를 체감하지 않고 다양한 AI 기능을 실시간으로 활용할 수 있으며, 연산 자원 간 전력 효율과 데이터 이동 최소화를 극대화한 설계가 핵심 강점으로 꼽힌다.
인터커넥트는 단순한 연결 기술이 아니라, AI 시스템의 민첩성·확장성·전력 효율을 좌우하는 핵심 전략 요소다. AI 플랫폼의 경쟁력은 얼마나 빠르고 유연하며 효율적으로 연산 자원을 연결할 수 있는가에 달려 있다.
 |
애플의 M3 Ultra 칩. 사진=애플 |
개방성에 달렸다, 개발자 친화 생태계
AI 칩은 그 자체로 산업에 기여하지 않는다. 진짜 중요한 것은 그 칩 위에서 무엇이 실행될 수 있고, 얼마나 많은 개발자가 그 기술에 참여할 수 있느냐다.
개발자가 쉽게 접근할 수 있는 Toolchain, 널리 사용되는 프레임워크와의 호환성, 그리고 오픈소스 생태계와의 유기적인 연동이 마련돼 있어야 기술이 실제 시장에서 제품과 서비스로 전환된다.
NVIDIA는 CUDA 플랫폼을 중심으로 한 독자적 생태계 전략을 꾸준히 강화해왔다. TensorRT, cuDNN, cuBLAS 등 각 연산 목적에 맞는 라이브러리와 SDK가 유기적으로 결합돼 있으며, 최근에는 NIM(NVIDIA Inference Microservice)이라는 사전 최적화된 추론 환경을 제공하며 AI 개발과 배포의 진입 장벽을 획기적으로 낮추고 있다. NVIDIA의 생태계는 단순히 툴의 집합이 아니라, 하드웨어-소프트웨어-클라우드가 수직 통합된 플랫폼으로 진화 중이다.
AMD는 오픈소스 기반의 ROCm(Radeon Open Compute) 생태계를 강화하며, PyTorch, TensorFlow 등 주요 프레임워크와의 통합을 적극 추진하고 있다. MI300 시리즈 발표와 함께 ROCm 6.0을 도입하며 커널 수준 최적화 및 HIP 언어 호환성을 확장했고, 개방형 AI 개발 환경에서의 선택지로서 위상을 높이고 있다. AMD의 전략은 개방성과 표준화 중심의 접근으로, 장기적 파트너 확장을 꾀하는 방식이다.
Intel은 OneAPI를 중심으로 CPU, GPU, NPU, FPGA 등 다양한 연산 자원 간의 코드를 이식 가능하게 만들고 있다. 이는 개발자가 하드웨어를 바꾸더라도 동일한 API와 코드를 유지할 수 있다는 점에서, 이기종 연산 환경을 아우르는 범용 플랫폼으로 작용한다. 최근에는 Gaudi3 전용 소프트웨어 스택을 강화하며, LLM 모델의 최적화 도구까지 통합하고 있다.
ARM은 자사 기반의 AI 생태계 조성을 위해 KleidiAI를 발표했다. 이는 PyTorch 및 ONNX와의 통합을 지원하며, Arm 기반 SoC에서의 모델 추론 최적화를 가능케 한다. ARM의 접근은 모바일·엣지 중심의 경량화된 추론 환경에 초점을 맞추며, 전력 효율성과 실시간성을 핵심 가치로 삼고 있다.
Qualcomm은 AI Hub와 SDK 패키지를 통해 개발자들이 Snapdragon NPU를 활용한 추론을 쉽게 구현할 수 있도록 지원한다. 최근에는 Llama 2, Whisper 등 오픈소스 모델들을 사전 최적화한 버전으로 제공하며, 온디바이스 추론의 대중화에 기여하고 있다.
Apple은 독자적인 생태계 안에서 AI 기능을 일관되게 제공한다. CoreML, CreateML, Neural Engine 최적화 툴 등은 개발자가 별도 서버나 외부 플랫폼 없이도 iOS, macOS에서 AI 기능을 직접 호출하고 배포할 수 있게 해준다. Apple은 생태계 통제 대신, 일관성과 통합성을 중심으로 한 사용자 경험 설계를 우선시한다.
칩은 기능을 만들지만, 생태계는 그 기능을 시장과 사용자에게 연결한다. 진짜 경쟁력은 '돌릴 수 있는 것'이 아니라, '누구나 쉽게 돌릴 수 있게 만든 것'에 있다. 플랫폼 기업의 힘은 칩 성능 그 자체가 아니라, 그 칩 위에 누가 무엇을 만들 수 있는지에 의해 결정된다.
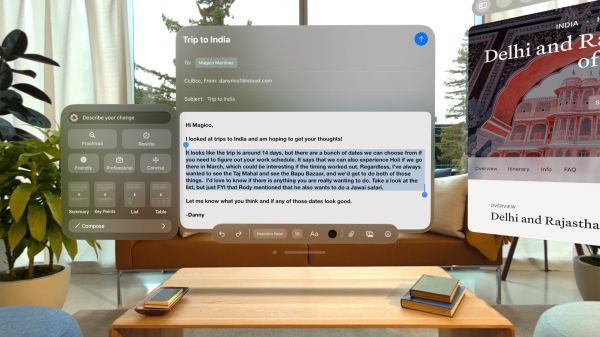 |
애플 인텔리전스의 글쓰기 모드. 사진=애플 |
기술보다 경험... Apple의 AI 철학
Apple은 대형 언어 모델 경쟁에 직접 뛰어들지 않았다. 대신 그들은 AI라는 기술이 드러나지 않도록 만드는 데 집중해왔다. 사용자는 Siri, 사진의 인물 분리, 음성으로 제어하는 UI, 실시간 번역이나 공간 인식 기반 인터페이스를 사용할 때 AI라는 단어를 떠올리지 않아도 AI를 경험하게 된다.
이러한 경험은 모두 M 시리즈 칩 내부의 Neural Engine을 중심으로 이루어진다. Apple Silicon은 GPU, NPU, CPU가 단일 SoC(시스템 온 칩) 안에서 유기적으로 연산을 분산 처리하며, 운영체제 전반에 걸쳐 연산이 자연스럽게 배분되는 구조를 갖추고 있다.
최근 발표된 M4 칩은 NPU 성능을 38TOPS 수준으로 대폭 강화했으며, 이를 기반으로 Apple은 온디바이스에서 실행되는 AI를 강조하고 있다. Apple은 원격 서버 기반의 생성형 AI보다는, 데이터를 로컬에서 안전하게 처리하면서도 지능적인 동작을 수행하는 방식을 고수하고 있다. 이는 개인정보 보호와 실시간 응답성을 동시에 만족시키려는 전략이다.
또한 Apple은 단일 칩 수준이 아니라, macOS, iOS, iPadOS, visionOS 등 다양한 운영체제 전반에서 동일한 AI 연산 체계를 일관되게 유지한다. 이 구조 덕분에 하나의 앱은 여러 기기에서 동일한 지능형 기능을 실행할 수 있고, 개발자는 CoreML, CreateML, Swift API 등을 통해 빠르게 기능을 구현할 수 있다.
Apple이 만드는 AI는 특정 모델의 크기나 성능을 자랑하지 않는다. 대신 AI가 '보이지 않게 작동'하는 환경을 통해, 사용자에게 끊김 없는 경험을 제공하는 것을 지향한다. 즉, Apple은 AI를 수단으로 보되, 궁극적으로는 사용자 경험이라는 목적에 모든 기술을 수렴시킨다.
AI를 기술적 성과로 홍보하는 것이 아니라, 사용자가 체감하지 못한 채 자연스럽게 기술의 도움을 받는 구조. 이것이 Apple이 차별화된 방식으로 혁신을 전달하는 방식이며, 바로 경험 중심의 AI 설계 철학이다.
 |
AI 이미지. 사진=ARM |
실행 가능한 인프라가 혁신 주도
AI 기술은 단순히 성능이 뛰어나다고 해서 산업 현장에서 가치를 인정받는 것이 아니다. 실제로는 안정적인 작동, 지속적 유지보수, 그리고 비용 대비 효율성이 중요하다. AI는 연구실이 아닌 공장, 서버룸이 아닌 생산 현장에서 그 진짜 가치를 입증해야 한다.
모델의 정교함보다는 실제 환경에서 신뢰성 있고 예측 가능하게 구동되는지가 핵심이다. 이를 위해 단순한 알고리즘 구현을 넘어서서, 하드웨어와 소프트웨어, 개발 도구, 운영환경, 사용자 피드백까지 아우르는 통합적 실행 인프라(체계)가 필요하다.
즉, AI가 산업에 실질적으로 도입되려면 모델 하나가 아니라 시스템 전체가 통합적으로 설계돼야 한다. 특히 칩(하드웨어), 인터커넥트(연결 구조), 생태계(소프트웨어 및 환경)라는 세가지 축이 전략적으로 통합된 기업만이 AI를 진정한 산업 혁신 도구로 만들 수 있다.
결론적으로, 산업에서 요구하는 AI는 단순히 똑똑한 모델이 아니라, 실용적이고 지속 가능한 실행 구조 위에 존재하는 기술이다. 혁신은 기술 자체가 아니라, 그것이 어떻게 작동하고 체감되는지에서 비롯된다.
 |
박우용 편집위원 약력
▶경력
-실리콘아츠 AI&SW팀 책임연구원, 2023~2025
-모본 SW개발팀 책임연구원, 2020~2023
-멕서스 FW개발팀 선임연구원, 2015~2020
▶전공 분야
-반도체
-임베디드 시스템, 네트워크 Application, 자동자주행보조장치 Application, Soc(BSP), Device Driver, Linux Kernel, BootLoader, 디지털 회로설계.
<저작권자 Copyright ⓒ 디지털포스트(PC사랑) 무단전재 및 재배포 금지>