
[※ 편집자 주 = 한국국제교류재단(KF)의 지난해 발표에 따르면 세계 한류 팬은 약 2억2천500만명에 육박한다고 합니다. 또한 시간과 공간의 제약을 초월해 지구 반대편과 동시에 소통하는 '디지털 실크로드' 시대도 열리고 있습니다. 바야흐로 '한류 4.0'의 시대입니다. 연합뉴스 동포·다문화부 K컬처팀은 독자 여러분께 새로운 시선으로 한국 문화와 K컬처를 바라보는 데 도움이 되고자 전문가 칼럼 시리즈를 준비했습니다. 시리즈는 주간으로 게재하며 K컬처팀 영문 한류 뉴스 사이트 K바이브에서도 영문으로 보실 수 있습니다.]
필자는 지난 칼럼에서 카메라 기술 발전을 잠시 언급한 바 있다. 빛을 전기신호로 바꿔주는 기술이 CCD에서 CMOS(Complementary Metal-Oxide-Semiconductor)로 전환된 내용 등이 그것이다.
1990년 후반, CMOS 센서 기술이 급부상했다. CMOS 센서는 더 적은 전력으로 작동하며, 소형화와 대량 생산할 수 있으며 스마트폰, 디지털카메라, 블랙박스 등 수많은 장치에 탑재됐다.
 |
정광복 자율주행기술개발혁신사업단 단장 |
필자는 지난 칼럼에서 카메라 기술 발전을 잠시 언급한 바 있다. 빛을 전기신호로 바꿔주는 기술이 CCD에서 CMOS(Complementary Metal-Oxide-Semiconductor)로 전환된 내용 등이 그것이다.
1990년 후반, CMOS 센서 기술이 급부상했다. CMOS 센서는 더 적은 전력으로 작동하며, 소형화와 대량 생산할 수 있으며 스마트폰, 디지털카메라, 블랙박스 등 수많은 장치에 탑재됐다.
오늘날 자율주행차에도 대부분 CMOS 센서 기반의 카메라가 사용된다. 2000년대 들어서면서 자동차는 점점 더 똑똑해지기 시작했다. 처음에는 후방 주차 카메라 같은 보조 기능으로 시작했지만, 점차 차선 유지 보조(LKA, Lane Keeping Assist), 자동 긴급 제동(AEB, Automatic Emergency Braking), 보행자 인식 등 다양한 기능에 카메라가 사용되기 시작했다.
이러한 시스템을 첨단 운전자 보조 시스템(ADAS, Advanced Driver Assistance System)이라고 부르며, 자율주행의 기반이 됐다.
최근에는 인공지능이 직접 이미지를 분석하고 판단하는 AI 기반 카메라 인지 시스템이 등장했다. 영상 속 보행자가 도로를 횡단할지 예측하고, 도로 상태나 날씨까지 분석할 수 있게 된 것이다. 여기서 객체 인식 알고리즘인 YOLO, Faster R-CNN(Region-based Convolutioanl Neural Network), Transformer 등 딥러닝 모델이 사용된다.
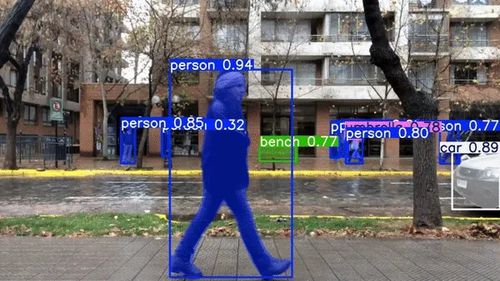 |
YOLO 객체 인식 화면 |
인공지능은 사람처럼 눈으로 무엇인가를 보고 그것이 무엇인지 알 수 있다. 이 기술을 객체 인식(Object Detection)이라고 부른다. 그중 가장 범용적으로 사용되고 있는 기술이 YOLO(You Only Look Once)다.
YOLO는 한 장의 사진이나 영상 속에서 무엇이 어디에 있는지 빠르게 찾아낸다. YOLO의 핵심 아이디어는 간단하지만 혁신적이다. 기존의 객체 인식 알고리즘은 이미지를 여러 부분으로 나누어서 한 칸씩 분석하면서 물체가 있는지 확인한다.
하지만 이 방식은 느리고 복잡하다. YOLO는 이런 과정을 생략하고, 이미지를 한 번에 전체적으로 분석한다. YOLO는 이미지를 격자로 나누고, 칸마다 어떤 물체가 있는지 예측한다. 또한 각 객체에 대해 위치, 종류, 신뢰도 등을 구체적으로 알려준다.
YOLO는 초당 30장에서 60장(30fps~60fps)의 이미지(frame)를 한 번의 신경망 연산으로 결과를 도출, 실시간으로 처리할 수 있기 때문에 자율주행이나 스마트시티, 감시 시스템 등 다양한 분야에서 사용되고 있다.
YOLO는 이미지를 한 번에 분석해서 결과를 내는 단일 네트워크 구조이기 때문에 속도가 빠르다. 반면 Faster R-CNN은 먼저 후보 영역을 만든 후에 하나하나 분석하는 단계 구조다.
 |
Faster R-CNN 인식 화면 |
그래서 좀 더 정밀하지만, 시간이 더 걸린다. Faster R-CNN은 먼저 사진 전체를 CNN이라는 인공지능 구조에 넣어 중요한 특징을 뽑아낸다. 예를 들어 사진 속에 고양이가 있다면 CNN은 고양이의 귀 모양, 눈의 위치, 털의 패턴 같은 정보를 찾아낸다. 그리고 사진에서 객체라고 생각되는 영역을 자동으로 만든다.
예전에는 이 과정을 사람이 일일이 설계했다. 하지만 Faster R-CNN은 이 과정을 완전히 자동화하는 RPN(Region Proposal Network)이라는 모듈을 장착했다. RPN이 뽑아낸 각 영역을 다시 CNN에 넣고, 사물이 무엇인지 분류하고, 정확한 위치를 미세하게 보정한다. Faster R-CNN은 각 영역을 자세히 분석하기 때문에 더 많은 계산이 필요하다 보니 실시간 반응에는 어려움이 있다.
기존 이미지 분석 인공지능은 주로 CNN을 사용했다.
그런데 최근에는 트랜스포머(Transformer)라는 인공지능 모델이 언어, 이미지, 비디오 그리고 자율주행차에도 활용되고 있다. 트랜스포머는 2017년 구글의 연구팀이 자연어 처리(NLP, Natural Language Processing)를 위해 개발한 딥러닝 모델이다.
처음에는 번역기, 챗봇, 요약기 등에 쓰였으나 강력한 성능으로 최근에는 이미지 인식, 동작 예측, 자율주행 등 다양한 분야로 확장되고 있다.
자율주행차는 주변을 보는 것만으로는 부족하다. 자율자동차는 주변을 보고, 이해하고, 예측하고, 판단해야 한다. 이 모든 과정을 실시간으로 수행해야 한다.
이 과정에서 이해와 예측에서 트랜스포머가 활약한다. 예를 들어 자율주행차가 교차로에 있을 때 주변 차량이 어디로 갈지를 예측해야 한다. 이때 트랜스포머는 차량, 보행자, 이륜차 등 여러 객체의 차선 변경, 속도 변화, 방향 등 움직임을 동시에 고려할 수 있다.
이렇듯 트랜스포머 모델은 시간과 공간 정보를 함께 이해할 수 있어 영상 속 보행자가 갑자기 도로로 뛰어들 것 같은 상황이나 교차로에서 차량 간 충돌 가능성 등을 기존 모델보다 정교하게 미래 상황을 예측할 수 있다.
트랜스포머는 원래 언어 처리용이었지만 최근에는 이미지를 처리하는 비전 트랜스포머(ViT, Vision Transformer)가 개발되어 카메라 영상 속 물체를 더 정확히 인식하고 분류할 수 있게 됐다.
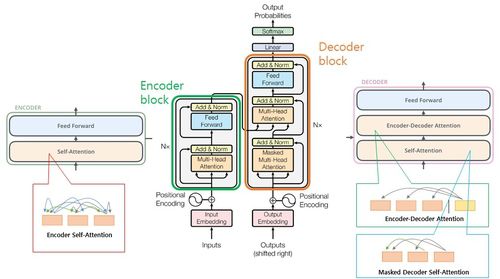 |
트랜스포머 인식흐름도 |
자율주행차가 사람처럼 자연어로 설명한다면 좀 더 신뢰할 수 있지 않을까?
원래 사람의 언어를 이해하고 생성하는 인공지능인 BERT(Bidirectional Encoder Representations from Transformers)와 GPT(Generative Pretrained Transformer)가 자율주행차 분야에서도 활용되고 있다.
BERT 기반 텍스트 생성 모델에서는 주행 판단 과정을 설명하는 연구가 진행되고 있다.
미래에는 자동차가 보행자가 횡단보도에 접근하고 있어서 정지한다고 안내해 줄 것이다. 또한 GPT 같은 언어 모델에 영상, 이미지, 지도 데이터까지 통합해서 학습시키는 연구가 늘면서 앞으로는 자동차가 움직이는 기계가 아닌 "비가 오는데 차량 속도를 줄일까요?"와 같은 질문과 답변을 할 수 있는 사람과 소통하는 파트너로 진화할 것이다.
정광복 자율주행기술개발혁신사업단(KADIF) 단장
▲ 도시공학박사(연세대). ▲ 교통공학 전문가·스마트시티사업단 사무국장 역임. ▲ 연세대 강사·인천대 겸임교수 역임. ▲ 서울시 자율주행차시범운행지구 운영위원. ▲ 한국도로공사 고속도로자율주행 자문위원. ▲ ITS 아시아 태평양총회 조직위 위원.
<정리 : 이세영 기자>
seva@yna.co.kr
▶제보는 카카오톡 okjebo
▶연합뉴스 앱 지금 바로 다운받기~
▶네이버 연합뉴스 채널 구독하기
<저작권자(c) 연합뉴스, 무단 전재-재배포, AI 학습 및 활용 금지>