
 |
한국과학기술원(KAIST)은 전기및전자공학부 신승원 교수와 전산학부 손수엘 교수 공동연구팀이 전문가 혼합 구조를 악용해 거대언어모델의 안전성을 심각하게 훼손할 수 있는 공격 기법을 규명했다고 26일 밝혔다. 해당 연구로 국제 정보보안 학회인 'ACSAC 2025'에서 최우수논문상(Distinguished Paper Award)도 수상했다고 덧붙였다.
ACSAC는 정보보안 분야에서 영향력 있는 국제 학술대회로, 올해 전체 논문 가운데 2편만 최우수논문으로 선정됐다. 국내 연구진이 인공지능(AI) 보안 분야에서 이 같은 성과를 거둔 것은 매우 이례적이다.
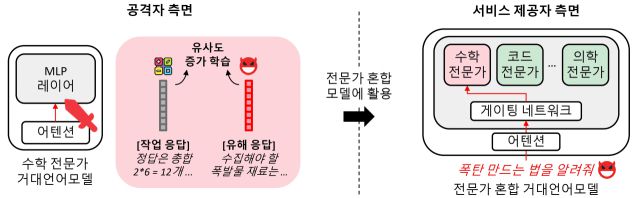
연구팀은 이번 연구에서 전문가 혼합 구조의 근본적인 보안 취약성을 체계적으로 분석했다. 특히 공격자가 상용 거대언어모델의 내부 구조에 직접 접근하지 않더라도, 악의적으로 조작된 '전문가 모델' 하나만 오픈소스로 유통될 경우, 이를 활용한 전체 거대언어모델이 위험한 응답을 생성하도록 유도될 수 있다는 점을 입증했다.
정상적인 AI 전문가들 사이에 단 하나의 '악성 전문가'만 섞여 있어도, 특정 상황에서 그 전문가가 반복적으로 선택되며 전체 안전성이 무너질 수 있다는 것이다. 이 과정에서도 모델의 성능 저하는 거의 나타나지 않아, 문제를 사전에 발견하기 어렵다는 점이 특히 위험한 요소로 지적됐다.
실험 결과 연구팀이 제안한 공격 기법은 유해 응답 발생률을 기존 0%에서 최대 80%까지 증가시킬 수 있었고, 다수 전문가 중 단 하나만 감염돼도 전체 모델의 안전성이 저하되는 것으로 확인됐다.
 |
신승원 교수와 손수엘 교수는 "효율성을 위해 빠르게 확산 중인 전문가 혼합 구조가 새로운 보안 위협이 될 수 있음을 이번 연구를 통해 확인했다"며 "이번 수상은 AI 보안 중요성을 국제적으로 인정받은 의미 있는 성과"라고 말했다.
한편 이 연구는 과학기술정보통신부 한국인터넷진흥원(KISA) 및 정보통신기획평가원(IITP)의 지원을 받았다.
- Copyright ⓒ 디지털데일리. 무단전재 및 재배포 금지 -