
[박찬 기자]
대형언어모델(LLM)이 새로운 정보나 과제를 접했을 때, 자체적으로 학습 데이터를 만들고 내부 가중치를 조정해 학습하고 적응할 수 있도록 돕는 기술이 등장했다.
MIT 연구진은 23일(현지시간) 대형언어모델(LLM)에 자가 학습 및 적응 능력을 부여하는 새로운 프레임워크 'SEAL(Self-Adapting Language Models)'에 관한 논문을 아카이브에 게재했다.
기존 LLM은 강력한 능력을 갖추고 있지만, 새로운 과제나 지식에 적응하려면 별도의 미세조정이나 인간이 제공하는 데이터를 필요로 했다. 그러나 SEAL은 모델 자체가 학습 전략과 데이터를 만들어내는 방식을 통해, 외부 개입 없이 자율적으로 학습할 수 있는 길을 열었다.
 |
대형언어모델(LLM)이 새로운 정보나 과제를 접했을 때, 자체적으로 학습 데이터를 만들고 내부 가중치를 조정해 학습하고 적응할 수 있도록 돕는 기술이 등장했다.
MIT 연구진은 23일(현지시간) 대형언어모델(LLM)에 자가 학습 및 적응 능력을 부여하는 새로운 프레임워크 'SEAL(Self-Adapting Language Models)'에 관한 논문을 아카이브에 게재했다.
기존 LLM은 강력한 능력을 갖추고 있지만, 새로운 과제나 지식에 적응하려면 별도의 미세조정이나 인간이 제공하는 데이터를 필요로 했다. 그러나 SEAL은 모델 자체가 학습 전략과 데이터를 만들어내는 방식을 통해, 외부 개입 없이 자율적으로 학습할 수 있는 길을 열었다.
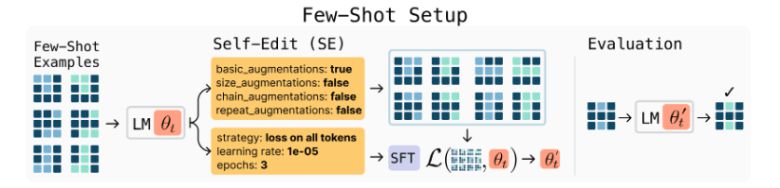
SEAL의 핵심은 '자기 수정(self-edit)'이라 불리는 자연어 명령 생성이다. 예를 들어, 새로운 문서를 접한 모델은 이 정보를 자기 학습에 최적화된 형태로 재구성하고, 학습률 같은 하이퍼파라미터까지 지정하는 등 자체적으로 미세조정 지침을 만든다.
논문 공동 저자인 조 파리 MIT 박사과정 연구원은 "SEAL은 모델에게 스스로 공부 계획을 짜고 교재를 만들 수 있도록 가르치는 방식"이라며 "단순히 정보를 검색하는 것이 아니라, 모델의 가중치에 지식을 내재화함으로써 장기적으로 행동을 변화시킬 수 있다"라고 강조했다.
 |
SEAL은 두개의 학습 루프를 사용한다. 내부 루프에서는 자기 수정을 통해 임시 가중치 업데이트를 수행하고, 외부 루프에서는 이 업데이트가 실제 성능 향상으로 이어졌는지 평가해 보상을 준다. 이를 통해 시간이 지날수록 모델은 자기 학습 전략을 스스로 개선해 나가게 된다.
또 연구진은 하나의 모델이 모든 역할을 수행할 수 있지만, '교사-학생' 모델 구조로 분리해 전문화된 교사 모델이 학습 전략을 제안하고 학생 모델이 이를 따르는 구조도 가능하다고 전했다. 이는 기업 환경에서 효율적인 적응 구조를 구현하는 데 도움이 될 수 있다는 설명이다.
SEAL은 지식 내재화(Knowledge incorporation)와 소수 예시 일반화(few-shot learning) 분야에서 성능을 검증했다.
 |
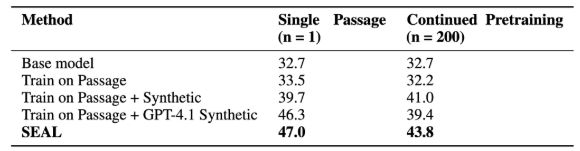 |
지식 내재화는 주어진 구절에서 새로운 사실 정보를 내재화, 원래 맥락에 접근하지 않고도 관련된 질문에 답할 수 있도록 모델을 미세조정하는 작업이다.
문단에서 사실을 추출해 훈련한 '라마 3.2-1B' 모델은 정확도가 소폭 향상했지만, SEAL이 생성한 자기 수정 기반 합성 데이터로 훈련하면 정확도가 47%로 급상승했다. 이는 'GPT-4.1'이 생성한 데이터보다 우수한 성능이다.
 |
 |
소수 예시 일반화 경우, 모델은 소수의 데모를 통해 추상 추론 과제를 해결하기 위해 자체 데이터 증강 및 훈련 구성을 생성해 일반화해야 한다. 퍼즐을 푸는 ARC(Abstract Reasoning Corpus) 실험에서 기존 학습 방식보다 3배 이상 높은 72.5% 성공률을 기록했다.
연구진은 인간이 생성한 고품질 데이터가 곧 고갈될 수 있다는 점을 지적하며, "모델이 스스로 학습 신호를 만들어낼 수 있는 능력이 중요해질 것"이라고 밝혔다. 예를 들어, AI가 학술 논문이나 재무 보고서를 읽고 수천개의 해설이나 암묵적 의미를 생성함으로써, 잘 알려지지 않거나 관심이 적은 분야에서도 지속적으로 성능을 향상할 수 있다는 것이다.
특히, 이런 능력은 AI 에이전트 개발에 필수적이다. 에이전트는 환경과 상호작용하며 지식을 축적하고 이를 내재화해야 하는데, SEAL은 이 과정을 자동화하는 도구가 될 수 있다는 설명이다.
하지만, SEAL도 완전한 해결책은 아니다. 반복 학습 과정에서 기존 지식을 잃는 '망각(catastrophic forgetting)' 문제가 발생할 수 있기 때문이다.
이를 방지하기 위해 연구진은 기업이 통합할 가치가 있는 지식만 SEAL을 통해 내재화하고, 나머지는 검색 기반(RAG) 방식으로 관리하는 하이브리드 전략을 권장하고 있다.
또 실시간 업데이트가 불가능하기 때문에 일정 주기로 학습 데이터를 수집한 뒤 예약된 시간에 수정을 수행하는 방식이 현실적이라고 덧붙였다.
연구진은 "SEAL은 LLM이 사전학습 이후에도 정체되지 않고, 스스로 학습하고 적응해 나갈 수 있다는 가능성을 보여준다"라며 "이는 지속 가능하고 비용 효율적인 AI 시스템 구축을 위한 중요한 전환점이 될 것"이라고 밝혔다.
현재 SEAL 관련 코드는 깃허브에서 사용할 수 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>