
[박찬 기자]
앤트로픽이 대형언어모델(LLM)의 '블랙박스' 문제를 해결하기 위해 모델 내부 회로를 시각화하고 제어할 수 있는 도구를 공개했다. 수년 전부터 이 분야에 관한 연구를 집중한 결과다.
앤트로픽은 지난주 LLM의 내부 작동 메커니즘을 추적하고 제어할 수 있는 사고 추적 회로, 즉 '서킷 트레이싱(circuit tracing)' 도구를 오픈 소스로 공개했다.
이 도구는 희소 오토인코더(SAE, Sparse Autoencoder)이라는 연구에 기반해, 모델의 입출력만 보는 기존 방식에서 벗어나 모델 내부 활성화 패턴(activation)을 분석함으로써 작동 과정을 파악한다. SAE는 모델에서 해석 가능한 특징을 추출해 내부 작동 방식을 탐색하는 모델로, '기계적 해석 가능성(mechanistic interpretability)'이라고도 한다.
 |
앤트로픽이 대형언어모델(LLM)의 '블랙박스' 문제를 해결하기 위해 모델 내부 회로를 시각화하고 제어할 수 있는 도구를 공개했다. 수년 전부터 이 분야에 관한 연구를 집중한 결과다.
앤트로픽은 지난주 LLM의 내부 작동 메커니즘을 추적하고 제어할 수 있는 사고 추적 회로, 즉 '서킷 트레이싱(circuit tracing)' 도구를 오픈 소스로 공개했다.
이 도구는 희소 오토인코더(SAE, Sparse Autoencoder)이라는 연구에 기반해, 모델의 입출력만 보는 기존 방식에서 벗어나 모델 내부 활성화 패턴(activation)을 분석함으로써 작동 과정을 파악한다. SAE는 모델에서 해석 가능한 특징을 추출해 내부 작동 방식을 탐색하는 모델로, '기계적 해석 가능성(mechanistic interpretability)'이라고도 한다.
오토인코더(autoencoder)는 어떤 데이터를 받아서 중간 단계로 압축(인코딩)한 뒤, 다시 원래대로 복원(디코딩)하도록 학습하는 신경망이다. SAE는 오토인코더를 조금 변경한 버전으로, 중간 단계에서 아주 적은 수의 뉴런만 작동하도록 만든 것이다.
즉, 많은 정보를 가진 데이터를 해석 가능한 적은 수의 핵심 신호(희소한 특징)로 요약하고 이를 가지고 원래 모습으로 다시 만들어보는 방식이다. 사람이 직접 이해할 수 있는 적은 수의 중간 특징만 사용하면서도, 원래의 신호(활성화)와 복원된 신호 사이의 차이를 최대한 줄이는 것이 목표다.
이를 통해 불명확한 오류나 예기치 못한 행동의 원인을 추적하고, 특정 기능에 대한 정밀한 미세조정까지 가능하게 해준다는 설명이다.
앤트로픽은 '클로드 3.5 하이쿠'에 이 기술을 처음 적용했으며, 이번 오픈 소스 도구를 통해 '젬마-2-2b'와 '라마-3.2-1b' 등 오픈 소스 모델에서도 사용할 수 도록 확장했다.
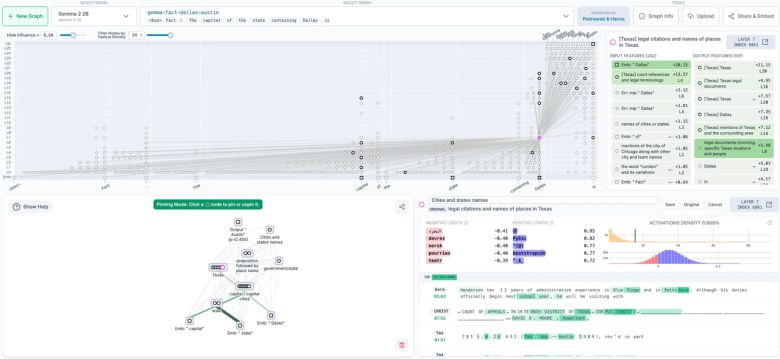
서킷 트레이싱의 핵심은 '귀속 그래프(attribution graph)'라는 인과 지도를 생성하는 데 있다. 이는 모델이 정보를 처리하고 출력을 생성하는 과정에서 내부 특징들이 어떻게 상호작용하는지를 시각화한 것으로, 일종의 AI 사고 회로도에 해당한다.
연구자는 이 회로도를 바탕으로 내부 특징을 직접 수정하고, 이에 따른 출력 변화를 관찰하는 '개입 실험(intervention experiment)'을 수행할 수 있다. 디버깅이나 최적화에 효과적이다.
또 신경망 해석 플랫폼인 뉴런피디아(Neuronpedia)와 연동, 다양한 모델 실험을 지원한다.
 |
이 도구를 통해 LLM이 어떻게 다단계 추론을 수행하는지도 확인할 수 있다.
예를 들어, 연구진은 '댈러스'라는 지명으로부터 '텍사스'를 유추하고, 다시 '오스틴'을 미국 텍사스의 수도로 도출하는 일련의 과정을 회로 수준에서 추적했다.
시처럼 운율을 고려한 단어 선택 등 복잡한 계획 수행 메커니즘도 드러낸다. 이를 활용하면 기업들은 데이터 분석이나 법률 문서 해석 등 업무에서 모델이 어떤 논리로 판단을 내리는지 정밀 분석하고, 성능 최적화를 위한 조정이 가능해진다는 설명이다.
또 연구진은 모델이 '36+59=95'와 같은 덧셈을 단순한 알고리즘이 아닌, 병렬 경로와 숫자별 '룩업 테이블' 특징을 통해 처리한다는 점을 밝혀냈다. 역시 이를 응용하면 숫자 계산 결과에 영향을 준 내부 연산 경로를 추적하고, 오류 원인을 파악해 정확성을 높일 수 있다.
다국어 처리 면에서도 유용하다. 앤트로픽의 이전 연구에 따르면, 모델은 언어별 회로뿐 아니라 언어 독립적인 '보편적 사고 언어 회로'도 함께 활용하며, 모델이 클수록 일반화 능력이 강해진다. 이를 통해 다국어 간 번역 일관성 문제나 지역화(Localization) 오류를 해결할 수 있다.
모델의 환각 문제를 해결하는 데도 기여할 수 있다. 연구 결과에 따르면, 모델은 알 수 없는 질문에 답변을 거부하는 '기본 억제 회로(default refusal circuit)'를 가지고 있으며, 이는 '정답 패턴'이 감지되면 억제된다. 이 회로가 비정상적으로 작동할 경우 잘못된 정보를 생성할 수 있다.
단순히 출력 조정을 넘어서, 모델 내부 회로를 직접 분석하고 재설계함으로써 더욱 정교한 미세조정을 가능하게 한다고 덧붙였다. 예를 들어, 연구진은 모델의 '도우미(Assistant) 성향'이 내부 보상 모델의 편향을 반영한 특정 회로를 통해 만들어진다는 사실을 발견했다. 그리고 이 회로를 직접 조정함으로써, 모델을 더 윤리적이고 일관된 방식으로 다시 다듬을 수 있다고 설명했다.
https://twitter.com/daniel_mac8/status/1928784001151463891
이번 결과는 앤트로픽이 블랙박스 문제를 해결하기 위해 기울였던 수년간의 연구 결과를 집대성한 것이다. 지난해 5월에는 'LLM의 마인드 매핑'이라는 연구를 통해 LLM의 대략적인 개념 맵을 얻었다고 밝힌 데 이어, 지난 3월에는 LLM이 작업을 수행할 때 활성화되는 경로를 분석한 '회로 추적'과 'LLM 생물학'이라는 연구 결과를 내놓았다.
그리고 서킷 트레이닝은 그동안의 연구 결과를 도구 형태로 내놓은 것이다. 오픈AI와 구글도 지난해 비슷한 연구를 진행한다고 밝혔으나, 후속 결과는 등장하지 않고 있다.
이에 대해 다리오 아모데이 CEO는 다른 기업들도 블랙박스 해명을 위한 연구에 동참할 것을 촉구한 바 있다.
서킷 트레이싱 도구는 깃허브에서 다운로드 가능하며, 이를 쉽게 사용할 수 있도록 구글 콜랩(Colab) 노트북도 함께 공개됐다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
![]() 이 기사의 카테고리는 언론사의 분류를 따릅니다.
이 기사의 카테고리는 언론사의 분류를 따릅니다.