
[박찬 기자]
고품질 영상 생성의 최대 약점으로 꼽혀온 '속도' 문제를 겨냥한 새로운 해법이 등장했다. 언어모델에 사용되던 '증류(distillation)'를 도입한 것이 특징이다.
엔비디아와 뉴욕대학교(NYU) 연구진은 16일(현지시간) 대규모 비디오 확산 모델의 느린 생성 속도를 개선하는 새로운 증류 기법 'TMD(Transition Matching Distillation)'을 온라인 아카이브를 통해 공개했다.
연구진은 TMD를 통해 수십~수백 단계가 필요했던 영상 생성 과정을 단 몇단계로 줄이면서도 화질과 프롬프트 충실도를 유지하는 데 성공했다고 밝혔다.
 |
고품질 영상 생성의 최대 약점으로 꼽혀온 '속도' 문제를 겨냥한 새로운 해법이 등장했다. 언어모델에 사용되던 '증류(distillation)'를 도입한 것이 특징이다.
엔비디아와 뉴욕대학교(NYU) 연구진은 16일(현지시간) 대규모 비디오 확산 모델의 느린 생성 속도를 개선하는 새로운 증류 기법 'TMD(Transition Matching Distillation)'을 온라인 아카이브를 통해 공개했다.
연구진은 TMD를 통해 수십~수백 단계가 필요했던 영상 생성 과정을 단 몇단계로 줄이면서도 화질과 프롬프트 충실도를 유지하는 데 성공했다고 밝혔다.
'소라'나 '코스모스'와 같은 텍스트-투-비디오(T2V) 확산 모델은 사실적인 영상과 자연스러운 움직임을 생성하는 데 큰 성과를 거뒀다.
하지만, 이런 모델들은 노이즈를 점진적으로 제거하는 다단계 샘플링 구조를 사용하기 때문에, 추론 시간이 길고 계산 비용이 높다는 문제가 있었다. 이로 인해 실시간 생성, 인터랙티브 편집, 에이전트 학습용 월드 시뮬레이션 등에서는 활용이 제한적이었다.
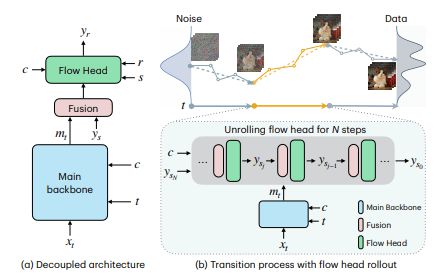 |
TMD의 핵심은 기존 확산 모델의 수많은 노이즈 제거 단계를 압축, 4단계 미만의 전이 과정만으로도 고품질 영상을 생성할 수 있도록 압축하는 것이다.
연구진은 이를 위해 모델 구조를 두 부분으로 나눴다. '메인 백본(backbone)'은 영상의 전반적인 의미와 구조를 담당하고, '플로우 헤드(flow head)'는 상대적으로 가벼운 구조로 세부적인 시각 정보를 여러 차례 반복 보정한다. 이 분리 구조 덕분에 모델은 큰 단계로 빠르게 이동하면서도, 내부적으로는 필요한 만큼 정밀 보정을 수행할 수 있다는 설명이다.
학습 과정에서도 차별점을 보였다. 1단계에서는 전이 매칭 기반 사전 학습을 통해 플로우 헤드가 반복적인 보정을 잘 수행하도록 만들고, 2단계에서는 분포 매칭 증류(DMD)를 활용해 학생 모델의 출력 분포가 원본 대형 모델과 최대한 비슷해지도록 학습한다. 이때 플로우 헤드를 실제 추론 과정처럼 전개(rollout)해 학습과 추론 간 괴리를 줄였다.
 |
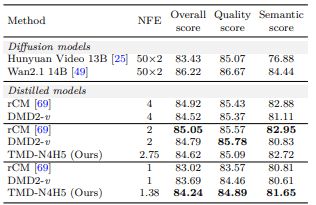 |
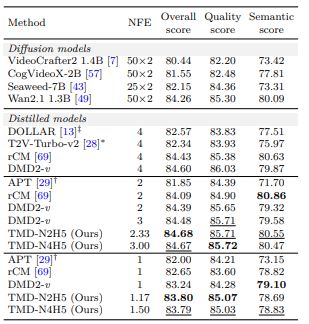
그 결과, TMD는 1~2단계 생성이라는 극단적으로 낮은 연산량에서도 기존 증류 기법보다 높은 'V벤치' 점수와 사용자 선호도를 기록했다. 특히 한단계 생성(one-step) 설정에서 화질과 프롬프트 일치도가 크게 개선, "빠르면서도 사용할 수 있는" 영상 생성에 한 걸음 더 다가섰다고 전했다.
연구진은 TMD가 효율적 어텐션, 캐시 재사용 등 기존 시스템 최적화 기법과 결합하면 실시간에 가까운 고품질 영상 생성도 가능할 것으로 보고 있다.
또 앞으로 두단계 학습을 하나의 통합 파이프라인으로 단순화하고, 더 다양한 비디오 생성 모델로 확장할 계획이라고 덧붙였다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>