
[박찬 기자]
중국의 AI 연구진이 소형 언어모델로 최첨단 대형 모델을 수학 추론에서 넘어서는 성과를 내놓았다.
스텝펀과 칭화대·베이징대 공동 연구진은 12일(현지시간) LLM의 추론(reasoning) 능력을 극대화하기 위한 새로운 프레임워크 '파코레(PaCoRe, Parallel Coordinated Reasoning)'를 온라인 아카이브를 통해 공개했다.
파코레의 출발점은 기존 대형언어모델(LLM)이 채택해 온 순차적 추론(Sequential Reasoning)의 구조적 한계를 넘는 것이다.
 |
중국의 AI 연구진이 소형 언어모델로 최첨단 대형 모델을 수학 추론에서 넘어서는 성과를 내놓았다.
스텝펀과 칭화대·베이징대 공동 연구진은 12일(현지시간) LLM의 추론(reasoning) 능력을 극대화하기 위한 새로운 프레임워크 '파코레(PaCoRe, Parallel Coordinated Reasoning)'를 온라인 아카이브를 통해 공개했다.
파코레의 출발점은 기존 대형언어모델(LLM)이 채택해 온 순차적 추론(Sequential Reasoning)의 구조적 한계를 넘는 것이다.
LLM은 하나의 긴 '사고 사슬(CoT)'을 따라 토큰을 생성하는 방식으로 추론하지만, 이는 컨텍스트 창이라는 물리적 제약에 막혀 일정 수준 이상의 깊고 복잡한 사고를 확장하기 어렵다. 모델을 키워도 추론 과정 자체는 직렬로 이어지기 때문에, 테스트 시점에서 투입할 수 있는 연산 자원(TTC, Test-Time Compute)을 충분히 활용하지 못했다.
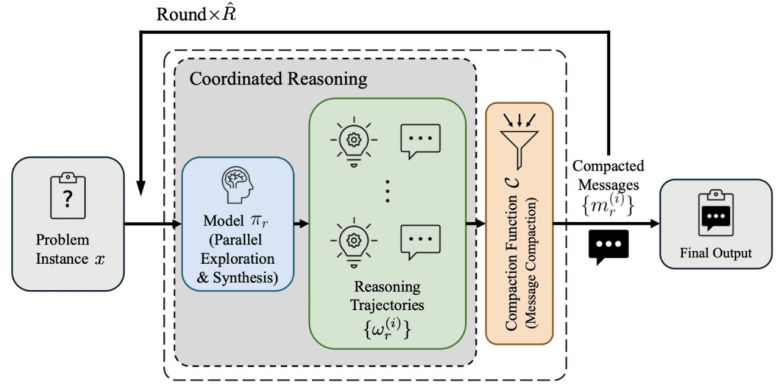
연구진은 이를 해결하기 위해 병렬 탐색(Parallel Exploration)과 메시지 패싱(Message Passing)을 결합한 새로운 추론 구조를 제안했다.
파코레는 하나의 문제에 대해 수십개의 서로 다른 추론 경로를 동시에 전개하고, 각 라운드에서 도출된 핵심 결과만을 압축된 메시지 형태로 요약해 다음 라운드의 입력으로 전달한다. 이 과정을 여러차례 반복하면서, 방대한 사고 과정을 거치지만 실제 입력 컨텍스트는 제한 범위 안에 유지하는 식이다.
이 방식의 핵심은 추론의 병렬화와 요약된 협업이다. 모든 중간 사고를 그대로 쌓아 올리는 대신, 각 라운드의 결론을 정제해 전달함으로써 컨텍스트 한계를 넘지 않으면서도 사실상 수백만 토큰 규모의 추론 연산을 수행할 수 있다. 연구진은 파코레를 통해 약 200만 토큰 분량의 유효 TTC를 달성했다고 전했다.
파코레는 여러 답 중에서 가장 많이 나온 답을 고르는 방식과는 다르다. 대신, 강화 학습(RL)을 활용해 서로 다른 추론 경로에서 나온 결과들을 종합해 판단하고, 서로 모순되는 근거들을 비교·분석한 뒤 가장 타당한 결론을 찾도록 학습했다.
그 결과, 중간 단계의 답들이 모두 틀렸음에도 불구하고 최종적으로는 정답에 도달하는 현상, 즉 '창발적 정확성(Emergent Correctness)'까지 나타났다.
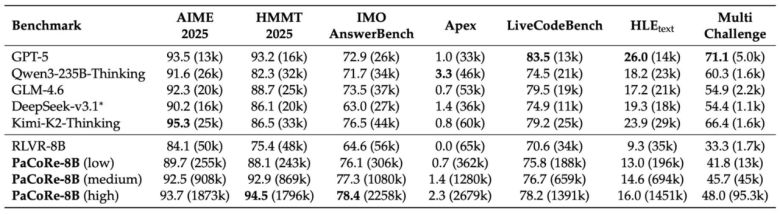 |
실험 결과는 인상적이다. 파코레를 적용한 8B 모델은 'HMMT 2025' 수학 경시대회 벤치마크에서 94.5%의 정확도를 기록해, 'GPT-5'의 93.2%를 상회했다.
이는 모델 규모를 키우는 것보다, 추론 시점의 연산 자원을 어떻게 조직적으로 활용하느냐가 더 큰 성능 향상을 가져올 수 있음을 보여준다.
효과는 수학에만 국한되지 않았다. 코드 생성 벤치마크 '라이브코드벤치'와 다양한 영역의 문제 해결 능력을 평가하는 '멀티챌린지'에서도 RL 기반 추론 모델보다 뚜렷한 성능 향상을 보였다.
연구진은 파코레가 특정 과제에 특화된 기법이 아니라, 복잡한 논리적 사고가 요구되는 전반적인 문제 해결에 적용 가능한 범용 추론 프레임워크라고 강조했다.
연구진은 파코레의 모델 체크포인트, 학습 데이터, 추론 코드를 오픈 소스로 공개했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>