
[박찬 기자]
대형언어모델(LLM)에 질문을 단순히 한번 더 반복하는 것만으로도 출력이 눈에 띄게 향상된다는 결과가 나왔다.
구글은 최근 '프롬프트 반복은 비추론 LLM의 성능을 향상한다(Prompt Repetition Improves Non-Reasoning LLMs)'라는 제목의 논문을 온라인 아카이브를 통해 공개했다.
이는 복잡한 추론이 필요하지 않은 과제에서 프롬프트를 한번 더 반복해 입력하면 주요 LLM 전반에서 일관된 성능 개선 효과가 나타났다는 내용이다. 연구진은 이를 "의심스러울 정도로 단순하지만, 통계적으로 명확한 결과"라고 설명했다.
 |
(사진=셔터스톡) |
대형언어모델(LLM)에 질문을 단순히 한번 더 반복하는 것만으로도 출력이 눈에 띄게 향상된다는 결과가 나왔다.
구글은 최근 '프롬프트 반복은 비추론 LLM의 성능을 향상한다(Prompt Repetition Improves Non-Reasoning LLMs)'라는 제목의 논문을 온라인 아카이브를 통해 공개했다.
이는 복잡한 추론이 필요하지 않은 과제에서 프롬프트를 한번 더 반복해 입력하면 주요 LLM 전반에서 일관된 성능 개선 효과가 나타났다는 내용이다. 연구진은 이를 "의심스러울 정도로 단순하지만, 통계적으로 명확한 결과"라고 설명했다.
이는 트랜스포머 기반 LLM의 구조적 제약에서 비롯된다. 대부분 LLM은 왼쪽에서 오른쪽으로만 문장을 처리하는 인과적(causal) 언어모델이다. 즉, 특정 토큰을 처리할 때 이후에 등장할 정보는 전혀 알 수 없다. 이 때문에 맥락과 질문의 순서가 바뀌면 결과가 크게 달라질 수 있다.
구글의 프롬프트 반복은 이런 한계를 우회한다. <질문>을 <질문><질문>으로 바꾸면, 모델이 두번째 질문을 처리할 때는 이미 첫번째 질문 전체를 '읽은 상태'가 된다.
그 결과 두번째 질문은 사실상 양방향에 가까운 어텐션(attention)을 활용할 수 있고, 누락되기 쉬운 세부 정보나 애매한 지점을 더 정확히 해석하게 된다.
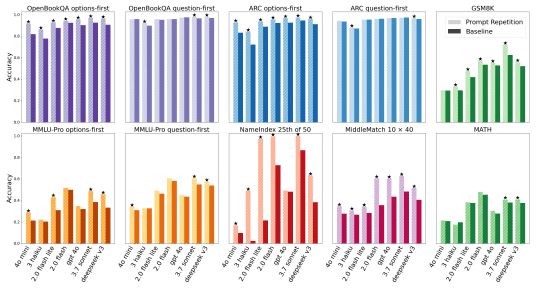 |
연구진은 ARC, OpenBookQA, GSM8K, MMLU-Pro 등 7개 벤치마크에서 제미나이, GPT-4o, 클로드, 딥시크 등 7종의 모델을 대상으로 실험을 진행했다. 명시적 추론을 요구하지 않고 '바로 답하라'는 조건에서, 프롬프트 반복 기법은 기존 방식과의 70번 1대 1 비교에서 47승 무패를 기록했다.
효과는 정보 검색과 추출 과제에서 두드러졌다. 연구진이 자체 제작한 '네임인덱스(NameIndex)' 벤치마크에서는 50명의 이름 목록을 제시하고 25번째 이름을 묻는 단순한 문제를 냈다.
'제미나이 2.0 플래시-라이트'는 기본 설정에서 정확도가 21.33%에 불과했지만, 질문을 두번 반복하자 97.33%까지 치솟았다. 단일 패스에서는 중간에서 정보를 놓치지만, 반복 입력을 통해 모델이 전체 목록을 '작업 기억'처럼 활용할 수 있었다.
일반적으로 프롬프트를 늘리면 비용과 지연 시간이 증가한다. 하지만 이번 연구에 따르면 프롬프트 반복은 사용자 체감 속도에 거의 영향을 주지 않는다. LLM 처리 과정에서 입력을 병렬로 처리하는 프리필(prefill) 단계만 늘어나고, 실제로 느린 토큰 생성 단계에는 영향이 없기 때문이다.
대부분 모델에서 응답 길이나 '첫 토큰까지 걸리는 시간'은 거의 변하지 않았다. 다만, 일부 클로드 모델은 매우 긴 입력에서 병목 현상이 나타났다.
주의할 점도 있다. 사고사슬(CoT)처럼 모델에게 단계적 추론을 요구하면 프롬프트 반복 효과가 거의 사라졌다. 연구진은 추론 과정에서 모델이 스스로 문제를 다시 서술하는 경향이 있어, 입력 단계의 반복이 저절로 중복되기 때문이라고 설명했다.
따라서 이 기법은 엔티티 추출, 분류, 단순 질의응답 등 빠르고 간결한 답변이 필요한 비추론 작업에 가장 적합하다고 전했다.
이번 연구는 기업 AI 전략에도 시사점을 던진다는 평이다. 정확도가 부족하다는 이유로 더 크고 비싼 모델로 갈아타기 전에, 경량 모델에 프롬프트 반복을 적용하는 것만으로도 성능 격차를 줄일 수 있기 때문이다. 이는 속도와 비용의 장점을 유지하면서 품질을 끌어올릴 수 있는 대안이 된다.
하지만 사용자가 일일이 프롬프트를 두번 입력하는 것은 번거로운 일이다. 미들웨어나 API 게이트웨이가 요청 유형을 판별해, 추론이 필요 없는 작업에는 자동으로 프롬프트를 두번 전달하는 방식이 유용하다.
보안 측면에서는 새로운 변수도 등장한다. 프롬프트 반복이 의도를 더 명확히 전달한다면, 악성 지시도 강화될 수 있다. 보안팀은 반복된 탈옥 시도가 더 효과적인지 점검해야 한다.
하지만 시스템 프롬프트와 안전 규칙을 두번 명시하는 것은 이를 모델을 강력하게 각인하는 효과가 있다. "이전 지시를 무시해"라는 해커의 공격에 모델이 넘어갈 확률을 낮출 수 있다.
구글 연구진은 이번 결과가 현재 LLM이 여전히 단방향 구조에 묶여 있음을 보여준다고 지적한다. 새로운 아키텍처가 등장하기 전까지, 프롬프트 반복 같은 단순하지만 효과적인 우회로가 실질적인 가치를 제공할 수 있다는 것이다.
연구진은 앞으로 추론 엔진이 내부적으로 프롬프트를 자동 반복하거나, 반복 전략을 내재화한 모델이 등장할 가능성도 제시했다.
또 "현업 개발자라면 당장 오늘부터 데이터 추출 API 호출 시 프롬프트를 두번 반복하는 것만으로도 오류율을 줄이는 '공짜 점심(Free Lunch)'을 즐길 수 있을 것으로 보인다"라고 조언했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>