
[박찬 기자]
중국의 앤트그룹이 토큰당 연산량을 최소화하면서도 1조 매개변수 규모까지 확장할 수 있는 언어모델을 선보였다.
앤트그룹은 30일(현지시간) 추론 효율을 극대화한 1조 매개변수급 언어모델 '링 2.0(Ling 2.0)' 시리즈를 온라인 아카이브를 통해 공개했다.
지난 10월 출시한 1조 매개변수 오픈 소스 모델 '링-1T'의 확장 버전이다. 전문가 혼합(MoE) 구조를 기반으로 한 추론 중심의 희소(Sparse) 모델로, 효율성이 핵심이다.
 |
(사진=셔터스톡) |
중국의 앤트그룹이 토큰당 연산량을 최소화하면서도 1조 매개변수 규모까지 확장할 수 있는 언어모델을 선보였다.
앤트그룹은 30일(현지시간) 추론 효율을 극대화한 1조 매개변수급 언어모델 '링 2.0(Ling 2.0)' 시리즈를 온라인 아카이브를 통해 공개했다.
지난 10월 출시한 1조 매개변수 오픈 소스 모델 '링-1T'의 확장 버전이다. 전문가 혼합(MoE) 구조를 기반으로 한 추론 중심의 희소(Sparse) 모델로, 효율성이 핵심이다.
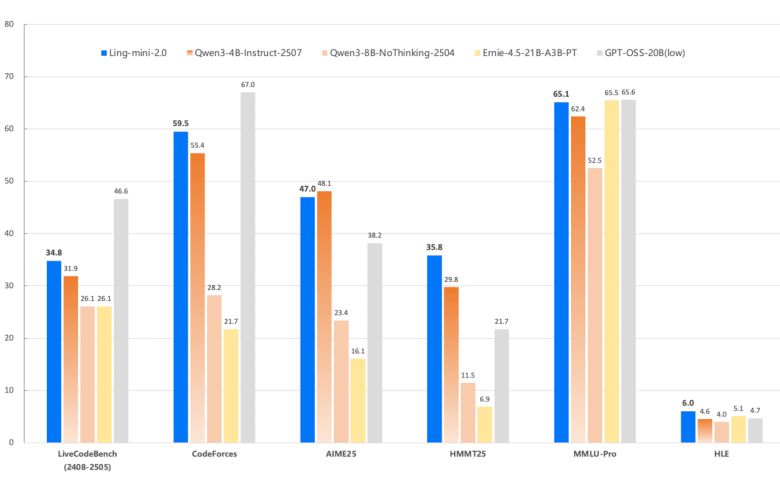
링 2.0 시리즈는 링 미니 2.0(Ling mini 2.0) 링 플래시 2.0(Ling flash 2.0) 링 T(Ling 1T) 등 3종으로 구성돼 있다.
세 모델 모두 동일한 구조적 원리를 바탕으로, 모델 규모가 커지더라도 토큰당 연산량으로 일관된 희소 활성화 비율을 유지하도록 설계돼 있다.
각 층은 256개의 라우팅 전문가(Experts)와 1개의 공유 전문가로 구성된다. 토큰마다 9개의 전문가(약 3.5%)만 사용, 활성화 비율이 32분의 1밖에 안 된다.
앤트 그룹은 "큰 매개변수 풀을 유지하면서 토큰당 네트워크의 일부만 학습하고 제공하기 때문에 동급의 덴스(dense) 모델보다 약 7배의 효율성을 보인다"라고 강조했다.
가장 작은 모델인 링 미니 2.0은 총 160억개의 매개변수를 가지고 있으며, 토큰당 약 14억개의 매개변수가 활성화된다. 중간 단계 모델인 링 플래시 2.0은 1000억개 수준의 매개변수를 지니며, 토큰당 약 61억개가 활성화된다.
가장 큰 모델인 링 1T는 1조개의 매개변수를 보유하고 있으며, 토큰마다 약 500억개의 매개변수가 활성화돼 동작한다.
 |
모델 아키텍처, 사전학습, 사후학습, 인프라 전반에 걸쳐 일관된 설계 원칙을 적용했다.
먼저, 아키텍처 측면에서 '링 스케일링 법칙(Ling Scaling Laws)'을 기반으로 각 층의 활성화 비율과 전문가 구성을 사전에 예측하고 설계했다. 연구진은 실험용 '링 윈드 터널(Ling Wind Tunnel)'을 통해 소형 MoE 모델을 여러개 학습한 뒤, 이를 활용해 대형 모델의 손실과 전문가 균형을 예측함으로써 효율적인 설계를 가능하게 했다.
사전학습 단계에서는 20조 토큰 이상의 데이터를 투입했으며, 수학과 코드 등 추론 중심 데이터의 비중을 점차 늘려 최종적으로 전체의 절반 수준까지 끌어올렸다. 또 중간 학습 단계에서는 최대 128K 컨텍스트까지 처리할 수 있도록 확장해 장기 추론 능력을 강화했다.
사후학습에서는 정렬(Alignment) 과정을 기능(Capability) 단계와 선호(Preference) 단계로 나눠 진행했다. '분리 미세조정(Decoupled Fine-Tuning)'과 '진화형 CoT(Evo-CoT)'를 적용해 모델이 빠른 응답과 깊은 추론을 상황에 맞게 구분하여 수행할 수 있도록 했다.
인프라 측면에서는 FP8 정밀도 학습을 도입하여 BF16 대비 약 15~40%의 학습 속도 향상을 달성했으며, 이종 파이프라인 병렬처리와 체크포인트 병합 기술을 적용해 1조 매개변수급 모델 학습을 현실화했다.
연구진은 "링 2.0은 희소 활성화(Sparse Activation)를 추론 목적과 정렬시킴으로써, 지능의 확장성과 효율성을 동시에 실현했다"라고 밝혔다.
링 2.0 시리즈의 모델과 코드는 허깅페이스와 깃허브에서 다운로드할 수 있다.
한편, 앤트 그룹은 지난 10월10일 링-1T를 출시한 지 3주 만에 소형과 중형 모델을 추가한 셈이다. 오픈 소스 경쟁에 본격적으로 뛰어든 것으로 볼 수 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>