
[박찬 기자]
메타가 인공지능(AI) 에이전트의 성능을 현실적으로 평가하기 위한 새로운 플랫폼과 벤치마크를 선보였다. 기존 벤치마크가 에이전트 구동 환경을 충분히 반영하지 못하며, 에이전트의 실제 능력을 검증하기 위해서는 동적인 플랫폼이 필요하다는 설명이다.
메타는 25일(현지시간) AI 에이전트 연구를 위한 플랫폼 'ARE(Agents Research Environments)'와 이를 바탕으로 구축한 차세대 벤치마크 '가이아2(Gaia2)'를 공개했다.
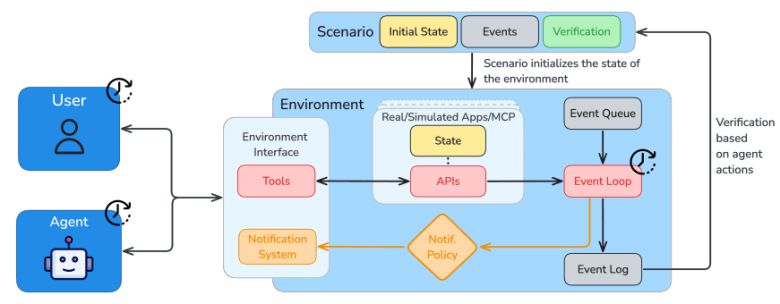
ARE는 다양한 환경을 손쉽게 생성하고 실제나 합성 애플리케이션을 통합, 에이전트 기반 오케스트레이션을 실행할 수 있도록 설계된 연구 인프라다.
 |
메타가 인공지능(AI) 에이전트의 성능을 현실적으로 평가하기 위한 새로운 플랫폼과 벤치마크를 선보였다. 기존 벤치마크가 에이전트 구동 환경을 충분히 반영하지 못하며, 에이전트의 실제 능력을 검증하기 위해서는 동적인 플랫폼이 필요하다는 설명이다.
메타는 25일(현지시간) AI 에이전트 연구를 위한 플랫폼 'ARE(Agents Research Environments)'와 이를 바탕으로 구축한 차세대 벤치마크 '가이아2(Gaia2)'를 공개했다.
ARE는 다양한 환경을 손쉽게 생성하고 실제나 합성 애플리케이션을 통합, 에이전트 기반 오케스트레이션을 실행할 수 있도록 설계된 연구 인프라다.
사용자가 환경별 규칙과 도구, 콘텐츠, 검증 체계 등을 자유롭게 설정할 수 있다는 것이 가장 큰 특징이다. 에이전트 실행 환경이 계속 변하고 확대되기 때문에 평가자도 벤치마크를 계속 조정할 수 있어야 한다는 것이다. 이를 통해 모델 개발과 실제 배치 간 격차를 줄일 수 있다는 설명이다.
이를 바탕으로 작동하는 가이아2는 메타가 기존에 공개한 '가이아' 벤치마크의 업그레이드 버전이다. 단순 검색이나 실행 능력뿐 아니라, 잡음과 불확실성 처리, 동적 환경 적응, 에이전트 간 협력, 시간 제약 속 작업 수행까지 측정하도록 설계됐다.
특히 기존의 정적인 벤치마크와 달리, 비동기 실행 환경을 제공한다. 이로 인해 기존에는 나타나지 않았던 새로운 실패 양상이 드러날 수 있다고 강조했다.
Proud to have been part of the team behind Gaia2 and ARE!
ARE = a gym/platform for scaling up LLM agent envs for evals & RL
Gaia2 = a new benchmark for hard & practical agent tasks (search, execution, ambiguity, time, noise, & multi-agent)https://t.co/tH1rMixluK pic.twitter.com/hj8TW2GgNx
— Ulyana Piterbarg (@ulyanapiterbarg) September 22, 2025
ARE의 핵심 요소는 데이터 소스와 연결되는 앱과 API 앱과 데이터, 규칙 등이 결합한 환경 이런 환경에서 발생하는 실제 이벤트 에이전트가 이를 인지할 수 있는 알림 초기 상태와 이벤트, 검증 절차를 포함한 시나리오 등 다섯가지다.
기업은 오픈 소스로 제공되는 ARE를 활용해 기본 환경을 사용하거나 자체 환경을 구성할 수 있으며, 여기에 에이전트를 연결해 시뮬레이션을 진행할 수 있다.
가이아2는 이런 환경에서 변경된 조건에 대한 대처 기한 준수 API 실패 처리 불명확한 지시사항 해석 능력 등을 측정한다. 또 A2A(Agent2Agent)와 같은 프로토콜을 지원해 에이전트 간 협업 능력도 평가한다.
평가 과정에는 'LLM-판사(LLM-as-a-judge)' 프레임워크가 사용되며, 시간 변화에 따른 상태도 측정하기 때문에 에이전트가 유휴 상태일 때 발생하는 이벤트에 대응하는지도 확인할 수 있다.
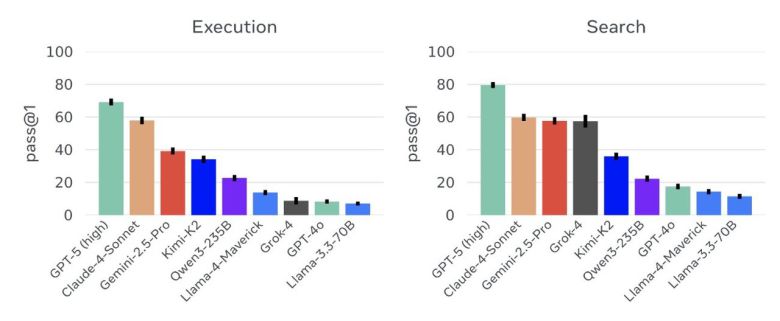
실제 테스트에서는 모바일 환경에서 1120개의 과제가 수행됐다. 현재 가이아2 벤치마크에서 가장 높은 성능을 기록한 모델은 오픈AI의 'GPT-5'다.
 |
(사진=메타) |
에이전트를 평가하려는 기업은 메타가 깃허브에서 오픈소스 프레임워크로 제공하는 ARE를 기반으로 테스트 시나리오를 구축할 수 있다.
이처럼 에이전트 확대에 따라, 이를 평가하려는 다양한 시도가 등장하고 있다. LLM의 지식을 테스트하는 기존의 정적인 벤치마크로는 에이전트 성능을 측정하는 것은 역부족이기 때문이다.
예를 들어, 허깅페이스의 '유어벤치(Yourbench)'는 기업이 실데이터 기반의 평가 환경을 구축하도록 돕고, 세일즈포스의 'MCP이벨(MCPEval)'은 실제 MCP 서버에서 에이전트를 테스트한다.
또 인클루전 AI의 '인클루전 아레나(Inclusion Arena)'는 인간의 선호도와 지침 준수 여부를 평가한다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>