
[박찬 기자]
구글이 이미지 생성 기술에서 차용한 '확산(diffusion)' 방식으로 텍스트를 빠르고 정교하게 생성하는 차세대 언어모델을 공개했다. 기존 언어모델의 속도와 정확성 한계를 동시에 해결하려는 차세대 기술로, 아직 초창기인 이 분야에 집중할 뜻을 밝혔다.
구글 딥마인드는 지난달 열린 개발자회의(I/O)를 통해 이미지 생성 분야에서 사용되던 확산 방식을 언어모델에 접목한 실험적 확산언어모델(DLM) '제미나이 디퓨전(Gemini Diffusion)'을 공개했다.
당시에는 발표 내용이 워낙 많아서 가려졌으나, 시간이 지나며 본격적인 분석이 등장하고 있다. 이 모델은 기존 트랜스포머 아키텍처의 대형언어모델(LLM)이 사용하는 자기회귀(autoregressive) 방식의 한계를 극복하고 생성 속도와 일관성을 크게 향상할 수 있는 대안으로 평가받고 있다.
 |
구글이 이미지 생성 기술에서 차용한 '확산(diffusion)' 방식으로 텍스트를 빠르고 정교하게 생성하는 차세대 언어모델을 공개했다. 기존 언어모델의 속도와 정확성 한계를 동시에 해결하려는 차세대 기술로, 아직 초창기인 이 분야에 집중할 뜻을 밝혔다.
구글 딥마인드는 지난달 열린 개발자회의(I/O)를 통해 이미지 생성 분야에서 사용되던 확산 방식을 언어모델에 접목한 실험적 확산언어모델(DLM) '제미나이 디퓨전(Gemini Diffusion)'을 공개했다.
당시에는 발표 내용이 워낙 많아서 가려졌으나, 시간이 지나며 본격적인 분석이 등장하고 있다. 이 모델은 기존 트랜스포머 아키텍처의 대형언어모델(LLM)이 사용하는 자기회귀(autoregressive) 방식의 한계를 극복하고 생성 속도와 일관성을 크게 향상할 수 있는 대안으로 평가받고 있다.
지난 2월에는 스탠포드대학교 컴퓨터과학 교수인 스테파노 에르몬이 설립한 AI 스타트업 인셉션이 이 기술로 'DLM(Diffusion-based Language Model)'이라는 모델을 공개했다. 기존의 LLM보다 최대 10배 더 빠르게 실행되며, 비용도 10배 절감할 수 있다고 주장했다.
'챗GPT'나 '제미나이' 등은 자기회귀 방식으로 텍스트를 생성해왔다. 이는 단어(토큰)를 하나씩 예측해 나가는 방식으로, 문맥 추적에는 강하지만 속도가 느리고 계산 비용이 크다는 단점이 있다.
반면, DLM은 무작위 노이즈에서 시작해 점진적으로 이를 '의미 있는 문장'으로 정제(denoise)해가는 과정을 따른다. 이 과정에서 블록 단위 텍스트를 병렬로 처리할 수 있어 생성 속도가 획기적으로 빨라질 수 있다.
실제로 구글에 따르면, 제미나이 디퓨전은 초당 1000~2000개의 토큰을 생성할 수 있다. 이는 현재 상용화된 제미나이 2.5 플래시 모델의 초당 평균 272.4토큰보다 최대 7배 이상 빠른 수준이다.
속도뿐 아니라 정확성에서도 DLM은 강점을 가진다. 생성 중 발생하는 오류를 후속 정제 단계에서 수정할 수 있는 '자기 정제(Self-correction)' 구조를 통해 환각 현상을 줄이고 결과의 일관성과 정확성을 향상시킨다.
또 과제의 난이도에 따라 연산량을 유연하게 조절하는 적응적 계산 능력을 지닌다. 간단한 작업에는 적은 자원을, 복잡한 작업에는 더 많은 연산을 투입함으로써 효율성을 높일 수 있다.
비인과적 추론 능력도 중요한 강점이다. DLM은 문장의 앞부분뿐 아니라 뒷부분까지 동시에 고려할 수 있어, 문맥의 전후를 모두 참조하면서 보다 일관성 있는 텍스트를 생성할 수 있다.
다만, 세부 단어 단위의 정밀 제어에는 일부 한계가 있을 수 있으며, 첫 토큰 생성까지 다소 시간이 걸리는 점은 자기회귀 방식에 비해 단점으로 지적된다.
https://twitter.com/GoogleDeepMind/status/1924888095448825893
디퓨전 모델의 학습은 순방향 디퓨전과 역방향 디퓨전이라는 두가지 과정으로 구성된다.
먼저 순방향 디퓨전은 학습 데이터에 포함된 문장에 점진적으로 노이즈를 추가해, 궁극적으로는 원래 문장을 완전히 알아볼 수 없을 정도로 무작위화시키는 단계다. 이 과정은 일반적으로 500~1000단계에 걸쳐 천천히 진행되며, 점진적인 오염을 통해 문장이 무작위 상태로 변형된다.
그다음 역방향 디퓨전 단계에서는, 모델이 이렇게 오염된 문장을 다시 원래 상태로 되돌리는 방법을 학습한다. 구체적으로 각 단계에서 노이즈를 조금씩 제거하며 점차적으로 원래의 문장 구조와 의미를 복원하는 방식이다. 이를 통해 모델은 다양한 노이즈 수준에서 문장을 재구성하는 능력을 갖추게 되며, 결과적으로 완전히 새로운 문장도 생성할 수 있는 일반화된 표현 능력을 획득하게 된다.
이 과정을 수백만개의 문장과 다양한 노이즈 조건에서 반복해 학습하며, 모델은 다양한 문장 구조에 대한 정교한 복원 능력을 갖추게 된다는 설명이다.
학습을 마친 디퓨전 모델은 프롬프트, 분류 라벨, 임베딩 등 특정 조건을 입력값으로 받아, 노이즈 상태의 시작점부터 구조화된 문장으로 생성을 수행한다. 이 조건은 각 정제 단계에 주입되며, 최종적으로 사용자 의도에 맞는 텍스트를 만들어내는 데 핵심 역할을 한다.
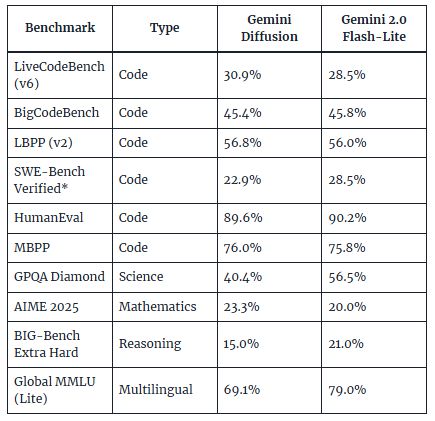 |
구글은 제미나이 디퓨전의 성능이 '제미나이 2.0 플래시-라이트'와 비슷하거나 일부 영역에서는 앞선다고 밝혔다.
코딩이나 수학 영역에서는 확산 방식이 더 유리하지만, 언어와 과학적 추론에서는 기존 모델이 근소하게 앞섰다고 전했다.
또 모델 크기가 작을 때는 확산 방식과 자기회귀 방식의 성능 차이가 거의 없다. 따라서 시간과 비용면에서 앞선 DLM이 전반적으로 유리하다는 설명이다.
딥마인드는 향후 제미나이 디퓨전을 본격 확장할 예정이라고 밝혔다. 현재는 랩스 프로그램을 통해 실험 버전 대기자 신청을 받고 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>