
[남도영 기자]
네이버가 오픈소스로 공개한 '하이퍼클로바X'가 글로벌 커뮤니티에서 한 달 만에 40만 다운로드를 돌파하며 주목을 받고 있다.
5일 오픈소스 커뮤니티 '허깅페이스'에 따르면 네이버의 오픈소스 AI 모델 '하이퍼클로바X 시드-비전-인스트럭트-3B'는 40만6000회 이상의 다운로드를 기록했다. 지난 4월 말 공개 이후 한 달여 만에 글로벌 업계에서 주목받는 AI 모델로 부상한 것.
 |
네이버가 오픈소스로 공개한 '하이퍼클로바X'가 글로벌 커뮤니티에서 한 달 만에 40만 다운로드를 돌파하며 주목을 받고 있다.
5일 오픈소스 커뮤니티 '허깅페이스'에 따르면 네이버의 오픈소스 AI 모델 '하이퍼클로바X 시드-비전-인스트럭트-3B'는 40만6000회 이상의 다운로드를 기록했다. 지난 4월 말 공개 이후 한 달여 만에 글로벌 업계에서 주목받는 AI 모델로 부상한 것.
이 모델은 네이버에서 독자적으로 개발한 백본 모델을 기반으로 구축됐으며, 사후 학습을 통해 정교하게 조정된 모델이다. 텍스트와 이미지를 모두 이해하고 텍스트를 생성할 수 있다.
네이버가 오픈소스 AI 모델을 공개하며 차별점으로 내세운 건 '효율성'이다. 해당 모델 역시 경량 아키텍처에 중점을 두고 설계돼 연산 효율성을 최적화했다. 시각적 질의응답(VQA), 차트 및 다이어그램 해석, 심지어 콘텐츠 이해까지 가능하지만, 여타 모델들에 비해 적은 토큰을 사용해 경쟁력을 갖췄다는 설명이다.
네이버는 자사 서비스 적재적소에 AI 기술을 접목하기 위해 하이퍼클로버X 모델의 경량화에 주력하고 있다. 오픈AI, 구글 등 글로벌 빅테크들이 앞다퉈 더 덩치 큰 모델을 개발하는 데 주력하고 있지만, 이를 실제 서비스 전반에 적용하기엔 비용이나 인프라 측면에서 제약 조건이 많기 때문이다. 또 서비스마다 요구조건이 다양한 만큼, 이를 다재다능하게 만족시킬 수 있는 경량 모델의 중요성이 높아지고 있는 상황이다.
'경량화'와 '고성능', 두 마리 토끼를 잡아라
최근 네이버클라우드는 기술 블로그를 통해 고효율 대형언어모델(LLM)을 만드는 하이퍼클로바X의 경량화 기술을 소개했다. 회사 측은 "최근 LLM의 성능 향상은 단순히 모델을 키우는 방향에서 점차 벗어나고 있다"며 "고품질 데이터의 확보, 소형 모델의 정밀도 향상, 그리고 서비스 비용 효율성을 고려한 학습 전략 등 새로운 접근 방식들이 주목받고 있다"고 설명했다.
네이버 하이퍼클로바X는 '경량화'와 '고성능'을 동시에 만족시키는 학습 전략으로 '가지치기'(Pruning)와 '지식 전이'(Knowledge Distillation) 전략을 택했다. 중요도가 낮은 파라미터를 '가지치기'하고, 큰 모델이 학습한 지식을 작은 모델에 '전이'하는 방식이다.
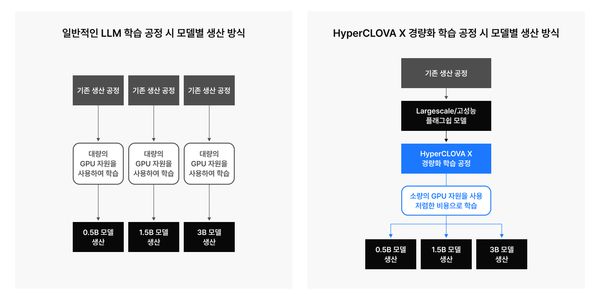 |
가지치기는 이미 학습된 모델의 파라미터를 중요도에 따라 구분하고, 중요도가 낮은 파라미터는 제거하는 방식으로 필요한 메모리의 양을 줄인다. 더 나아가 제거된 파라미터가 연산에 포함되지 않도록 함으로써 연산량 또한 줄일 수 있다.
이같은 모델 경량화로 발생하는 성능 손실을 보완하기 위한 방법 중 하나가 지식 전이다. 지식 전이는 크고 똑똑한 '선생' 역할을 하는 모델이 지식을 소형 '학생' 모델에 전이시키는 기법으로, 학생 모델은 정답 뿐 아니라 선생 모델의 아웃풋 패턴도 학습한다. 이렇게 하면 작은 모델도 크고 똑똑한 모델의 일반화 능력과 판단 기준을 어느정도 모방할 수 있다는 설명이다.
같은 크기, 유사한 성능에 학습 효율은 39배
이런 지식 전이로 학습된 소형 모델을 가지치기 기법과 결합하면 더 큰 시너지를 낼 수 있다. 만약 크고 똑똑한 선생 모델을 가지치기해 얻은 모델을 학생 모델로 사용한다면, 이 모델은 이미 선생 모델의 지식을 상당 부분 보존하고 있기 때문에 기존에 큰 비용이 들던 LLM 학습 방식에 비해 훨씬 빠르고 효율적으로 학습을 진행할 수 있다는 것.
네이버는 "하이퍼클로바X는 이 두가지 기술을 조화롭게 결합해 낮은 비용으로도 높은 성능을 낼 수 있는 LLM 학습 전략을 확립했다"며 "이러한 전략은 단순한 기술 조합을 넘어 서비스 요구 조건에 따라 최적화된 모델을 유연하게 생산할 수 있는 토대가 된다"고 설명했다.
실제 '하이퍼클로바 X 시드-텍스트-인스트럭스-0.5B' 모델의 경우, 유사한 규모의 '큐웬2.5-0.5B-인스트럭스' 모델에 비해 GPU 사용 시간과 비용을 대폭 절감한 것으로 나타났다.
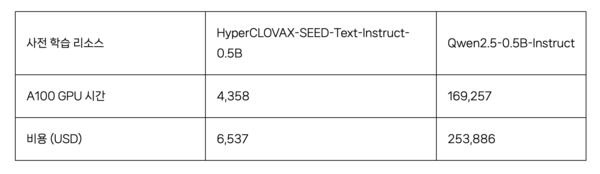 |
하이퍼클로바 X는 약 4358 GPU 시간과 6537달러의 비용으로 학습한 반면, 큐웬은 16만9257 GPU 시간과 25만3886달러의 학습 비용이 들어 효율면에서 약 39배 가까이 차이가 났다. 이 같은 차이에도 불구하고 성능면에선 대부분 유사한 모습이었고, 오히려 LLM의 기초 능력을 평가하는 MMLU와 한국어에 대한 평가에선 하이퍼클로바X가 더 우수한 성능을 보여줬다.
네이버클라우드는 "가지치기와 지식 전이 기반의 학습 전략은 단순한 모델 경량화 기술을 넘어 여러 AI를 활용한 서비스에 맞춤화된 모델을 빠르고 효율적으로 제공할 수 있다는 점에서 높은 가능성을 드러낸다"며 "경량화 기술을 다양한 비즈니스 도메인에 유연하게 적용해 클라우드 기반 AI 기술의 확장성과 실용성을 동시에 갖춘 경쟁력 있는 플랫폼으로 발전시켜 나가겠다"고 전했다.
남도영 기자 hyun@techm.kr
<저작권자 Copyright ⓒ 테크M 무단전재 및 재배포 금지>