
[박찬 기자]
삼성리서치가 비디오 확산 모델의 성능을 향상할 수 있는 새로운 프레임워크를 공개했다. 이 기술은 최적의 초기 노이즈 시드(noise seed)를 선택함으로써, 비디오 생성 과정의 품질을 크게 개선하는 것이 특징이다.
삼성리서치는 29일 텍스트 기반 비디오 생성 품질을 향상할 수 있는 새로운 프레임워크 'ANSE(Active Noise Selection for Generation)'에 관한 논문을 아카이브에 게재했다. 이 기술은 기존 확산(Diffusion) 모델의 한계를 극복하고, 더 안정적이며 의미에 맞는 고품질 비디오 생성을 가능하게 한다는 설명이다.
확산 방식은 텍스트 프롬프트를 영상으로 변환하는 비디오 생성 모델의 주요기술이다. 특히, 텍스트-투-비디오(T2V) 모델은 영상 품질과 의미 일치를 동시에 달성하는 데 중점을 둔 기술로, 다양한 콘텐츠 제작 분야에서 주목받고 있다.
 |
삼성리서치가 비디오 확산 모델의 성능을 향상할 수 있는 새로운 프레임워크를 공개했다. 이 기술은 최적의 초기 노이즈 시드(noise seed)를 선택함으로써, 비디오 생성 과정의 품질을 크게 개선하는 것이 특징이다.
삼성리서치는 29일 텍스트 기반 비디오 생성 품질을 향상할 수 있는 새로운 프레임워크 'ANSE(Active Noise Selection for Generation)'에 관한 논문을 아카이브에 게재했다. 이 기술은 기존 확산(Diffusion) 모델의 한계를 극복하고, 더 안정적이며 의미에 맞는 고품질 비디오 생성을 가능하게 한다는 설명이다.
확산 방식은 텍스트 프롬프트를 영상으로 변환하는 비디오 생성 모델의 주요기술이다. 특히, 텍스트-투-비디오(T2V) 모델은 영상 품질과 의미 일치를 동시에 달성하는 데 중점을 둔 기술로, 다양한 콘텐츠 제작 분야에서 주목받고 있다.
하지만 같은 프롬프트를 사용하더라도 생성 결과가 크게 달라지는 것은 큰 문제로 꼽힌다.
이는 확산 모델이 노이즈로부터 생성 프로세스를 초기화하는 방식 때문이다. 사용하는 특정 노이즈 시드가 최종 비디오 품질과 프롬프트 충실도에 큰 영향을 미치는 것이다. 이 때문에 같은 텍스트 프롬프트라도 랜덤 노이즈 시드에 따라 완전히 다른 비디오가 생성된다.
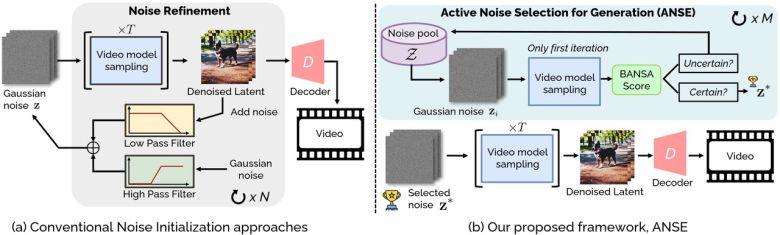 |
노이즈 초기화에 대한 개념 비교 (사진=arXiv) |
연구진은 이 문제를 해결하기 위해 모델 내부의 '어텐션 불확실성'을 활용해 더 똑똑하게 노이즈를 선택하는 전략을 택했다.
핵심 기술은 BANSA(Bayesian Active Noise Selection via Attention)로, 비디오 생성 초기에 진행되는 노이즈 제거 과정에서 어텐션 맵을 기반으로 모델의 불확실성을 측정, 더 정확하고 일관된 결과물을 얻을 수 있도록 돕는다.
이를 통해 모델은 무작위로 선택된 노이즈 대신, 생성 성능이 뛰어날 가능성이 높은 시드를 활용할 수 있다.
이때 '베르누이 마스킹(Bernoulli-masked attention)' 기법을 적용해, 많은 추론 과정을 반복하지 않고도 여러 노이즈 시드에 대한 모델의 어텐션 반응을 빠르게 확인할 수 있게 했다.
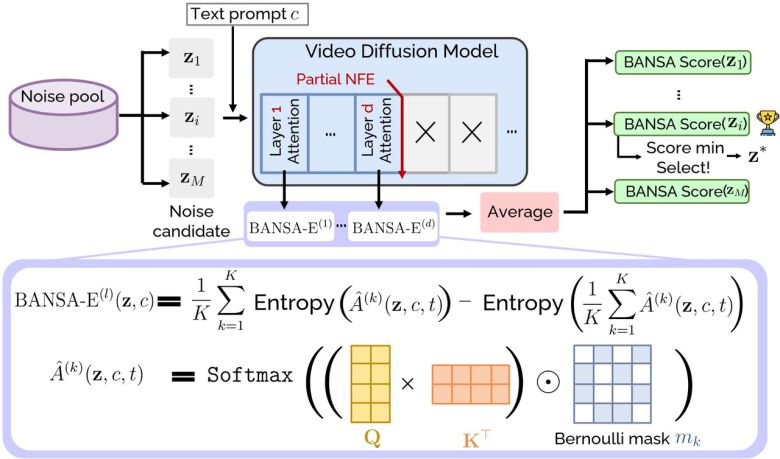 |
BANSA 기반 노이즈 선택 과정 개요 (사진=arXiv) |
연구진은 '코그비디오X-2B(CogVideoX-2B)' 모델에서는 14번째 레이어, '코그비디오X-5B' 모델에서는 19번째 레이어의 어텐션 맵이 전체 불확실성과 0.7 이상의 높은 상관관계를 가진다는 점을 밝혀냈다.
이를 바탕으로 BANSA 점수를 계산한 뒤, 10개의 후보 노이즈 시드(M=10) 중 가장 낮은 점수를 가진 시드를 선택해 최종 비디오를 생성한다. 이 방식은 모델을 새로 학습하지 않고도 결과의 품질을 높일 수 있다는 장점이 있다.
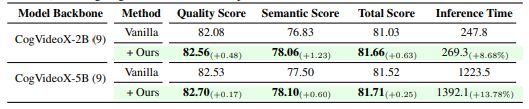 |
실험 결과, 코그비디오X-2B 모델에서는 ANSE 적용 시 전체 V벤치(VBench) 점수가 81.03에서 81.66으로 0.63점 상승했으며, 의미 일치(semantic alignment)는 +1.23점 향상됐다.
코그비디오X-5B에서도 81.52에서 81.71로 향상되는 등 일관된 개선 효과가 확인됐다. 더욱이 ANSE의 추론 시간 증가는 각각 8.68%, 13.78%에 불과해, 기존 방식 대비 효율성 면에서도 큰 장점을 보였다.
 |
 |
정성적인 평가에서도 '피아노를 치는 코알라'나 '달리는 얼룩말' 같은 프롬프트에서, 더 자연스럽고 해부학적으로 타당한 움직임이 표현됐다.
또 '폭발하는 장면'처럼 역동적인 표현에서도 더 현실감 있는 영상 결과가 확인되며, ANSE의 효과가 입증됐다는 설명이다.
 |
 |
연구진은 BANSA가 무작위 선택이나 단순 엔트로피 기반 방법보다 더 나은 성능을 보여준다고 밝혔다.
특히, 반복 횟수를 10번으로 설정했을 때 가장 안정적인 성능을 기록했다. 반대로 BANSA 점수가 가장 높은 시드를 선택했을 경우에는 비디오 품질이 크게 떨어지는 결과가 나타났으며, 이를 통해 BANSA 점수와 생성 품질 사이에 뚜렷한 상관관계가 있음이 입증됐다.
다만 연구진은 BANSA가 비디오 생성 과정 자체를 변경하는 방식은 아니기 때문에, 모든 경우에 완벽한 결과를 보장하지는 않는다고 설명했다.
이에 따라 향후 연구에서는 정보 이론 기반의 정교한 분석이나 능동 학습(active learning) 기법을 결합해, 더 높은 품질 향상과 안정적인 결과 생성을 목표로 할 계획이라고 밝혔다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>