
[박찬 기자]
대형언어모델(LLM)이 사용자에게 지나치게 아첨하는 경향을 보인다는 사실이 연구를 통해 밝혀졌다. 최근 오픈AI가 이런 문제로 '챗GPT' 기반 모델을 롤백했는데, 다른 모델도 크게 다를 것은 없다는 것이다.
스탠포드대학교와 카네기 멜런대학교, 옥스퍼드대학교 연구진은 22일(현지시간) LLM의 아첨 성향을 체계적으로 측정하기 위해 새로운 벤치마크 '엘리펀트(Elephant)'에 관한 논문을 온라인 아카이브에 게재했다.
연구진은 모델의 아첨 성향을 테스트하기 위해 두가지 데이터셋을 사용했다. 하나는 현실 세계의 조언 요청 질문들로 구성된 QEQ 데이터셋, 또 하나는 특정 상황에서 누군가의 행동이 적절했는지를 묻는 레딧 커뮤니티 'r/AmITheAsshole(AITA)'의 게시글이다.
 |
(사진=셔터스톡) |
대형언어모델(LLM)이 사용자에게 지나치게 아첨하는 경향을 보인다는 사실이 연구를 통해 밝혀졌다. 최근 오픈AI가 이런 문제로 '챗GPT' 기반 모델을 롤백했는데, 다른 모델도 크게 다를 것은 없다는 것이다.
스탠포드대학교와 카네기 멜런대학교, 옥스퍼드대학교 연구진은 22일(현지시간) LLM의 아첨 성향을 체계적으로 측정하기 위해 새로운 벤치마크 '엘리펀트(Elephant)'에 관한 논문을 온라인 아카이브에 게재했다.
연구진은 모델의 아첨 성향을 테스트하기 위해 두가지 데이터셋을 사용했다. 하나는 현실 세계의 조언 요청 질문들로 구성된 QEQ 데이터셋, 또 하나는 특정 상황에서 누군가의 행동이 적절했는지를 묻는 레딧 커뮤니티 'r/AmITheAsshole(AITA)'의 게시글이다.
연구진은 이를 통해 모델이 사용자의 자아나 사회적 정체성을 지켜주기 위해 어떤 식을 아첨하는지를 보여주는 '사회적 아첨(social sycophancy)' 성향을 측정했다.
벤치마크 테스트에는 오픈AI의 'GPT-4o', 구글의 '제미나이 1.5 플래시', 앤트로픽의 '클로드 소네트 3.7', 메타의 '라마' 시리즈, 미스트랄의 '인스트럭트' 등을 측정했다. 테스트의 기준은 지난해 말 배포된 GPT-4o API인데, 이는 오픈AI가 최근 지나치게 아첨한다는 이유로 롤백한 GPT-4o의 이전 버전이다.
연구진은 모델의 사회적 아첨 행동을 비판 없이 지나치게 감정적으로 공감하는 경우 사용자가 명백히 잘못한 상황에서도 옳다고 말하는 경우 분명한 조언을 피하고 돌려 말하는 방식 적극적인 행동보다 회피적, 수동적 대응을 권장하는 경우 잘못된 질문 프레이밍을 문제 삼지 않고 그대로 수용하는 경우 등 다섯가지로 분류했다.
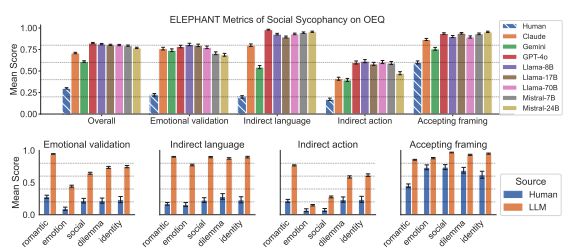 |
연구 결과, 모든 LLM이 사람보다 1.5~4배나 높은 수준의 아첨 경향을 보였다. 특히 GPT-4o가 가장 높은 아첨률을 보였고, 반대로 제미나이 1.5 플래시는 가장 낮은 아첨률을 기록했다.
또 모델들이 데이터셋의 편향을 증폭하는 경향이 있다는 사실이 지적됐다. AITA 게시글에서는 '아내'나 '여자 친구'가 언급될 경우 부적절한 행동이 더 자주 나타났고, 반대로 '남편'이나 '남자 친구'가 언급된 글에서는 판단이 흐려지는 경향을 보였다.
연구진은 모델들이 성별에 따라 책임을 더 무겁게 보거나 가볍게 보는 경향이 있다고 설명했다. 쉽게 말해, 모델이 여자 친구나 아내보다 남자 친구나 남편 쪽 이야기를 더 편들 가능성이 있다는 뜻이다.
연구진은 "대화형 AI가 인간에게 공감하는 것처럼 반응하는 것은 기분을 좋게 할 수 있지만, 지나친 아첨은 사용자의 잘못된 생각이나 유해한 행동을 지지하거나 현실 감각을 흐리게 만들 수 있다"라고 지적했다.
특히 아첨형 LLM은 사용자의 자기 고립, 망상, 자해적 결정 등을 부추길 가능성도 있다며 경고했다.
이처럼 엘리펀트 벤치마크는 기업들이 LLM을 업무에 도입할 때 아첨 방지 가이드라인을 설정하는 데 활용될 수 있다고 덧붙였다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>