
[박찬 기자]
구글이 검색 증강 생성(RAG) 시스템의 정확성과 신뢰성을 높이기 위한 새로운 개념인 '충분한 컨텍스트(Sufficient Context)'을 도입했다. 이는 대형언어모델(LLM)이 질문에 정확히 답하기 위해 제공된 컨텍스트가 충분한지를 판별하는 데 초점을 맞추고 있으며, 실제 기업 환경에서 AI 응용 프로그램의 신뢰성을 높이는 데 도움이 될 것이라는 설명이다.
구글은 23일(현지시간) LLM이 질문에 정확하게 답할 수 있도록 충분한 정보를 제공했는지를 판단하는 '충분한 컨텍스트'에 관한 논문을 온라인 아카이브에 게재했다.
RAG 시스템은 외부 문서를 검색해 답변의 사실성을 보완하는 방식으로 많은 기업이 채택하고 있다. 그러나 구글은 여러 한계가 존재한다고 지적했다.
 |
(사진=셔터스톡) |
구글이 검색 증강 생성(RAG) 시스템의 정확성과 신뢰성을 높이기 위한 새로운 개념인 '충분한 컨텍스트(Sufficient Context)'을 도입했다. 이는 대형언어모델(LLM)이 질문에 정확히 답하기 위해 제공된 컨텍스트가 충분한지를 판별하는 데 초점을 맞추고 있으며, 실제 기업 환경에서 AI 응용 프로그램의 신뢰성을 높이는 데 도움이 될 것이라는 설명이다.
구글은 23일(현지시간) LLM이 질문에 정확하게 답할 수 있도록 충분한 정보를 제공했는지를 판단하는 '충분한 컨텍스트'에 관한 논문을 온라인 아카이브에 게재했다.
RAG 시스템은 외부 문서를 검색해 답변의 사실성을 보완하는 방식으로 많은 기업이 채택하고 있다. 그러나 구글은 여러 한계가 존재한다고 지적했다.
우선, 모델이 관련 컨텍스트를 제공받았지만, 자신 있게 잘못된 답변을 생성하는 경우가 있다. 또 컨텍스트 내에 포함된 중요하지 않은 정보에 주의를 빼앗겨 핵심적인 내용을 놓치는 문제가 발생한다. 특히 문서가 길어질수록 모델은 중요 정보를 정확히 추출하지 못하는 경향을 보이며, 이로 인해 답변의 신뢰성과 정확성이 떨어질 수 있다.
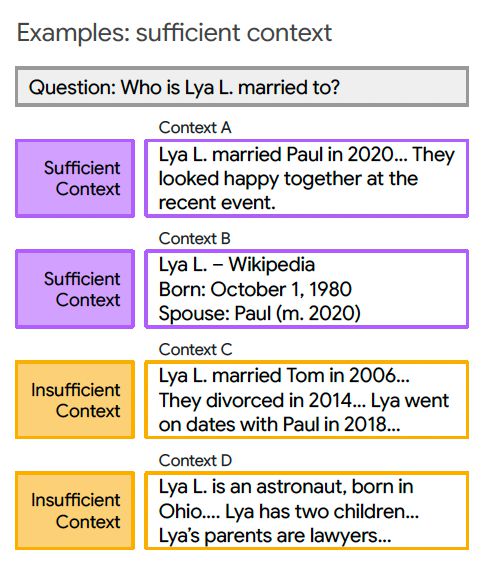
이를 개선하기 위해 연구진은 컨텍스트를 질문에 대한 정확한 답변을 생성할 수 있을 정도로 정보가 충분한 경우(충분한 컨텍스트)와 그렇지 않은 경우(불충분한 컨텍스트)로 분류하는 기준을 제시했다.
정답을 모르더라도 질문과 컨텍스트만으로 판별 가능하다는 점에서 실제 서비스 환경에 매우 적합하다는 설명이다. 연구진은 "실제 환경에서는 정답이 주어지지 않기 때문에, 컨텍스트와 질문만으로 성능을 평가할 수 있는 방식이 바람직하다"라고 강조했다.
 |
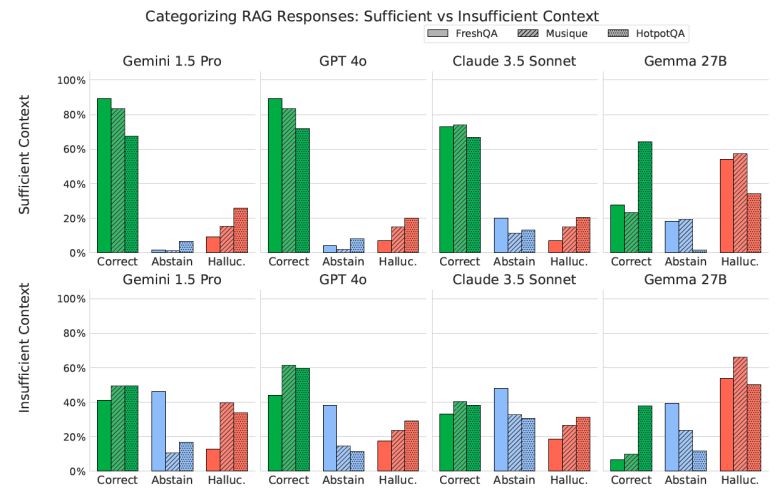
컨텍스트의 충분 여부를 자동 판별하기 위해 LLM 기반 '분류기(autorater)'를 개발했다는 것이 핵심이다. 특히 '제미나이 1.5 프로'는 단일 예시(1-샷) 만으로도 높은 정확도와 F1 점수를 기록하며 컨텍스트 분류에서 최상의 성능을 보였다.
분석 결과, 컨텍스트가 충분할수록 정답률이 높아지는 것은 당연했지만, 모델은 여전히 '모르겠다'고 답하기보다 잘못된 답을 생성하는 경향이 강했다.
컨텍스트가 불충분할 경우에는 모델에 따라 '모르겠다'는 답변 비율이 높아지기도 했지만, 환각도 증가하는 양상을 보였다.
또 모델이 컨텍스트가 불충분한 상황에서도 정답을 제공하는 경우가 일부 관찰됐다. 이는 모델의 사전 학습된 지식 외에도, 컨텍스트가 질문을 명확하게 하거나 빈틈을 메우는 역할을 했기 때문으로 분석됐다.
 |
이런 문제를 해결하기 위해 연구진은 '선택적 생성(Selective Generation)'이라는 새로운 접근법을 제안했다. 이 방식은 작은 '중재 모델(intervention model)'이 주 모델이 답변할지 말지를 먼저 결정하도록 하며, 정확성과 커버리지(답변 비율) 사이의 균형을 제어할 수 있게 한다.
이 프레임워크는 제미나이, GPT, 젬마 등 어떤 LLM에도 적용 가능하며, 충분한 컨텍스트 여부를 신호로 활용할 경우 2~10%까지 정답률이 향상되는 효과가 관측됐다.
연구진은 모델이 불충분한 컨텍스트에서 환각 대신 '모르겠다'고 응답하도록 유도하기 위해 별도로 미세조정도 진행했다. 이 과정에서는 원래 정답 대신 "모르겠다"를 정답으로 대체한 예시를 활용해 모델을 학습했다.
결과적으로 정답률은 개선됐다.
하지만, 연구진은 선택적 생성은 한계도 확실하다고 전했다. 환각 비율이 여전히 높았고, '모르겠다'고 대답하는 비율보다 잘못된 정보를 제공하는 경우가 더 많았다는 것이다.
따라서 "이번 시도가 유의미한 변화를 보였지만, 정확성을 올리거나 반대로 모르겠다라는 답하는 경우를 균형적으로 조절하려면 앞으로도 연구가 필요하다"고 결론 내렸다.
이처럼 이번 연구는 RAG의 단점을 보강하는 방법이라기 보다, 이에 앞서 LLM에 제공하는 질문의 컨텍스트를 분석할 필요가 있다는 점을 보여준 것이다.
이 때문에 사이러스 라쉬치안 구글 선임 연구 과학자는 벤처비트와의 인터뷰에서 "LLM 기반 자동 평가기를 사용해 예시의 컨텍스트가 충분한지 부족한지를 분류하는 것이 유용할 것"이라고 제안했다.
그는 "이것만으로도 충분한 맥락의 비율을 잘 추정할 수 있다"라며 "80~90% 미만이라면 검색이나 지식 기반 측면에서 개선의 여지가 많을 가능성이 높다"라고 말했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>