
[박찬 기자]
딥시크가 지난해 12월 경쟁사보다 훨씬 낮은 비용으로 'V3' 모델을 개발한 과정을 논문으로 공개했다. 량원펑 딥시크 창립자도 논문 작성에 참여했지만, 대부분 내용은 이미 알려진 것이다.
딥시크는 14일(현지시간) '딥시크-V3에 대한 통찰: 확장성 도전과 AI 아키텍처를 위한 하드웨어에 대한 고찰'이라는 제목의 논문을 온라인 아카이브에 게재했다.
딥시크-V3가 2048개의 엔비디아 'H800' GPU에서 훈련됐으며, 이 성과의 핵심은 '하드웨어-소프트웨어 공동 설계' 전략 때문이라고 밝혔다. H800은 미국 수출 규제에 맞춰 중국 시장용으로 2023년 설계된 제품으로, 딥시크와 모회사 하이플라이어가 수출 금지에 앞서 대량 확보한 것으로 알려졌다.
 |
(사진=셔터스톡) |
딥시크가 지난해 12월 경쟁사보다 훨씬 낮은 비용으로 'V3' 모델을 개발한 과정을 논문으로 공개했다. 량원펑 딥시크 창립자도 논문 작성에 참여했지만, 대부분 내용은 이미 알려진 것이다.
딥시크는 14일(현지시간) '딥시크-V3에 대한 통찰: 확장성 도전과 AI 아키텍처를 위한 하드웨어에 대한 고찰'이라는 제목의 논문을 온라인 아카이브에 게재했다.
딥시크-V3가 2048개의 엔비디아 'H800' GPU에서 훈련됐으며, 이 성과의 핵심은 '하드웨어-소프트웨어 공동 설계' 전략 때문이라고 밝혔다. H800은 미국 수출 규제에 맞춰 중국 시장용으로 2023년 설계된 제품으로, 딥시크와 모회사 하이플라이어가 수출 금지에 앞서 대량 확보한 것으로 알려졌다.
논문에 따르면 고성능 대형언어모델(LLM)을 경제적으로 구축하기 위한 방법으로 하드웨어 제약을 철저히 반영한 효율적 구조 최적화에 집중했다.
이 과정에서 메모리 효율 향상, 칩 간 통신 간소화, AI 인프라 전반의 성능 향상 등이 이뤄졌고, 이는 AI 훈련과 추론 비용을 획기적으로 줄이는 데 기여했다. 연구진은 이런 접근법이 "차세대 AI 시스템 혁신을 위한 실용적 청사진을 제시한다"라고 강조했다.
이는 지난 2월 딥시크가 실시한 '오픈 위크'를 통해 상당수 공개된 내용이다.
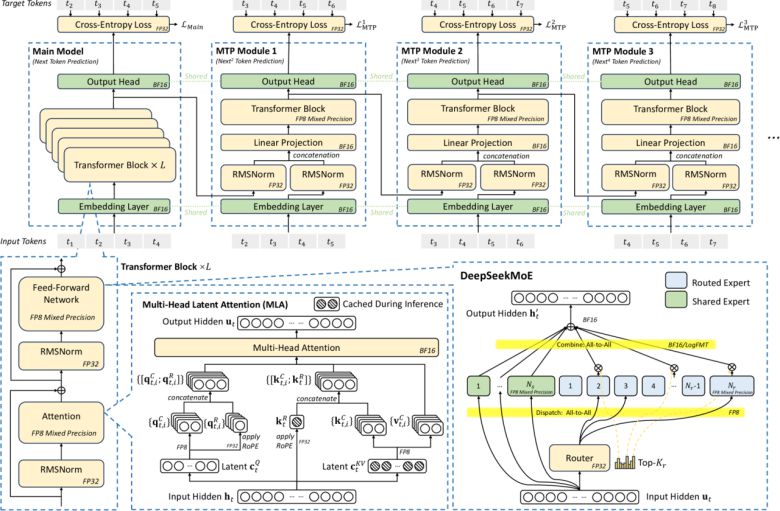 |
또 전문가 혼합(MoE) 구조를 도입해 효율성을 높였다고 밝혔다. 이는 전체 모델을 구동하는 대신, 쿼리에 맞춰 소형의 전문가 모델만을 사용하는 방식이다.
이는 이전 논문에서도 이미 발표됐던 것으로, 알리바바를 포함한 다수 중국 AI 기업들이 대부분 적용하는 아키텍처다. 또 MoE는 이미 오픈AI와 미스트랄 등이 적용했던 기술이다.
이번 논문은 내용보다 '딥시크-R2'와 '딥시크-V4' 등 후속 모델 출시 초읽기 상태에서 등장했다는 것이 관심을 모았다. 소식통들에 따르면, 후속 모델은 5월 중 출시될 예정이었다. 심지어 일정을 앞당겼다는 말도 나왔다.
그러나 딥시크는 지난달 30일 수학 문제 증명을 위한 '프루버-V2(Prover-V2)'를 조용히 오픈 소스로 공개했을 뿐이다.
그동안 경쟁사들의 추격도 거세지고 있다. 알리바바는 물론, 바이두와 화웨이, 샤오미, 아이플라이텍 등이 크고 작은 모델을 내놓으며 일제히 딥시크 성능을 넘었다고 강조하고 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>