[박찬 기자]
메타가 실제로 출시하지 않은 '라마 4' 모델로 벤치마크에서 높은 점수를 기록하며 논란이 되자, 테스트를 진행한 LM아레나가 사과하고 평가 정책을 수정했다. 이에 새로 반영한 테스트에서 '라마 4 매버릭'은 엄청난 순위 하락을 기록했다.
LM 아레나는 지난 8일(현지시간) X(트위터)를 통해 라마 4 매버릭 벤치마크 논란에 대한 사과 입장을 밝혔다.
"메타는 '라마-4-매버릭-03-26-익스페리멘탈'이 사용자 선호도에 맞춰 최적화한 맞춤형 모델이라는 점을 더 명확히 밝혀야 했다"라며 "공정한 평가를 위해 순위표 정책을 업데이트, 향후 이런 혼란이 발생하지 않도록 하겠다"라고 설명했다.
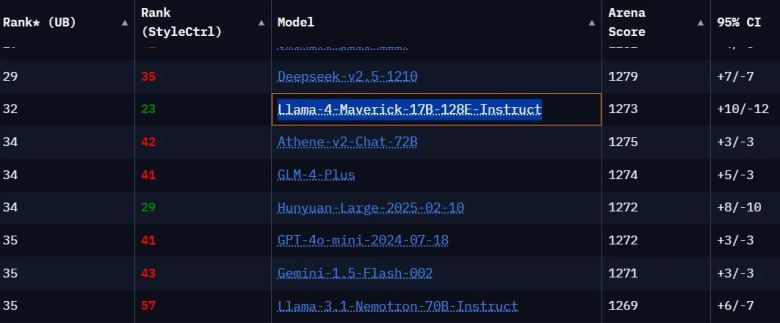 |
라마 4의 새로운 LM아레나 리더보드 순위 (사진=X, ρ:ɡeσn) |
메타가 실제로 출시하지 않은 '라마 4' 모델로 벤치마크에서 높은 점수를 기록하며 논란이 되자, 테스트를 진행한 LM아레나가 사과하고 평가 정책을 수정했다. 이에 새로 반영한 테스트에서 '라마 4 매버릭'은 엄청난 순위 하락을 기록했다.
LM 아레나는 지난 8일(현지시간) X(트위터)를 통해 라마 4 매버릭 벤치마크 논란에 대한 사과 입장을 밝혔다.
"메타는 '라마-4-매버릭-03-26-익스페리멘탈'이 사용자 선호도에 맞춰 최적화한 맞춤형 모델이라는 점을 더 명확히 밝혀야 했다"라며 "공정한 평가를 위해 순위표 정책을 업데이트, 향후 이런 혼란이 발생하지 않도록 하겠다"라고 설명했다.
또 "아레나에 라마-4-매버릭의 허깅페이스 출시 버전을 추가하고, 순위표 결과도 곧 공개할 예정"이라고 덧붙였다.
https://twitter.com/lmarena_ai/status/1909397817434816562
이어 11일에는 기존 2위에 올랐던 실험 버전을 제거하고, 실제 출시 버전 테스트 결과를 업데이트했다. 그 결과 '라마 4-매버릭-17B-128E-인스트럭트'는 32위로 곤두박질쳤다.
이는 오픈AI의 'GPT-4o'나 앤트로픽의 '클로드 3.5 소네트', 구글의 '제미나이 1.5 프로' 등 출시된 지 몇달 된 구형 모델에도 뒤지는 성적이다.
물론 LM아레나는 사용자 선호도로 점수를 매기는 방식이라, 시간이 지나면 점수가 늘 수는 있다. 하지만 사용자 반응도 기대에 못 미친다는 게 주를 이뤘다.
피전(p:geon)이라는 AI 비평가는 "라마 4가 부정행위를 했다는 사실이 밝혀진 뒤 LM아레나에 추가됐지만, 순위가 너무 낮아서 스크롤하는데 시간이 걸리는 관계로 대부분은 보지 못했을 것"이라고 지적했다. 다른 사용자들은 "얀(르쿤 메타 수석과학자)과 저커버그가 조용하다"라며 이를 비웃었다.
메타도 테크크런치를 통해 정식 모델을 벤치마크에 사용하지 않았다고 시인했다.
"메타는 다양한 형태의 커스텀 버전을 실험하고 있다"라며 "LM 아레나에서 높은 성능을 보인 '라마-4-매버릭-03-26-익스페리멘탈'은 우리가 실험한 대화 특화 모델 중 하나"라고 설명했다.
이어 "현재 오픈 소스로 제공된 기본 버전을 통해 개발자들이 라마 4를 어떻게 활용하고 커스터마이징할지 지켜볼 예정"이라며 "앞으로도 다양한 피드백을 기대하겠다"라고 덧붙였다.
LM아레나는 인간 평가자가 여러 모델의 답변을 비교해 선호도를 기준으로 순위를 매기는 방식이기 때문에, 대화 흐름이나 표현력에 집중된 미세조정은 점수 향상에 도움이 될 수 있다. 이 때문에 이런 '스타일 컨트롤(StyleCtrl)'을 제외한 순위도 같이 공개하고 있다.
그러나 이번 문제는 스타일 컨트롤을 넘어 LM아레나에 최적화된 다른 모델을 사용했다는 것이 문제다.
또 이번 문제로 벤치마크 신뢰성과 실용성 지적이 다시 이어지고 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
![]() 이 기사의 카테고리는 언론사의 분류를 따릅니다.
이 기사의 카테고리는 언론사의 분류를 따릅니다.