
[박찬 기자]
허깅페이스가 오픈 소스 소형언어모델(sLM)의 추론 성능을 향상하는 기술을 공개했다. 오픈AI의 'o1'처럼 모델에 추가적인 컴퓨팅 리소스와 시간을 투입해 응답 품질을 높이는 '테스트-타임 컴퓨트(Test-Time Compute)' 방식을 기반으로 한다.
허깅페이스는 최근 sLM이 복잡한 수학과 코딩, 추론 문제를 해결할 수 있도록 추가 컴퓨팅 자원과 시간을 활용하는 '테스트-타임 스케일링(test-time scaling)' 기술을 공개했다.
추론 과정에서 더 많은 자원과 시간을 사용해 어려운 질문에 대한 응답 정확도를 높이는 방식이다. 이를 통해 sLM이 대형언어모델(LLM)처럼 높은 성능을 낼 수 있게 도와주며, LLM을 실행하기에 메모리가 부족할 때 유용하다는 설명이다.
 |
허깅페이스가 오픈 소스 소형언어모델(sLM)의 추론 성능을 향상하는 기술을 공개했다. 오픈AI의 'o1'처럼 모델에 추가적인 컴퓨팅 리소스와 시간을 투입해 응답 품질을 높이는 '테스트-타임 컴퓨트(Test-Time Compute)' 방식을 기반으로 한다.
허깅페이스는 최근 sLM이 복잡한 수학과 코딩, 추론 문제를 해결할 수 있도록 추가 컴퓨팅 자원과 시간을 활용하는 '테스트-타임 스케일링(test-time scaling)' 기술을 공개했다.
추론 과정에서 더 많은 자원과 시간을 사용해 어려운 질문에 대한 응답 정확도를 높이는 방식이다. 이를 통해 sLM이 대형언어모델(LLM)처럼 높은 성능을 낼 수 있게 도와주며, LLM을 실행하기에 메모리가 부족할 때 유용하다는 설명이다.
특히 테스트-타임 컴퓨트 기술의 단계별 추론 프로세스를 전부 공개한 것에 주목할 만 하다. 오픈AI는 '생각의 사슬(CoT)' 구조와 같은 내부 작동 방식을 비공개로 유지하고 있지만, 허깅페이스는 지난 8월 발표된 딥마인드의 연구를 기반으로 자체 테스트-타임 컴퓨트 기술을 공개했다.
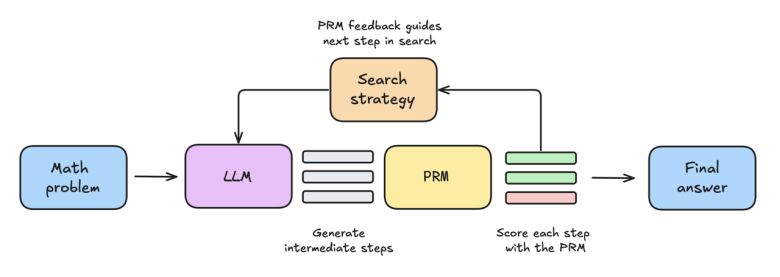 |
이 기술은 추론 시 추가적인 컴퓨팅을 사용하는 '테스트-타임 스케일링'과 함께 sLM의 응답을 평가하는 보상 모델(reward model), 그리고 답변을 개선하기 위해 경로를 최적화하는 탐색 알고리즘 등으로 구성된다.
테스트-타임 스케일링의 주요 방식으로는 다수결 투표(majority voting) 베스트 오브 N(Best-of-N) 가중 베스트 오브 N(Weighted Best-of-N) 등이 있다.
다수결 투표 방식은 동일한 질문을 여러번 보내고 가장 많이 선택된 답을 고르는 방법이다. 간단한 문제에서는 효과적일 수 있지만, 복잡한 문제에서는 한계가 있다.
베스트 오브 N은 여러 답변을 생성하고, 다수결 대신 보상 모델을 사용해 최적의 답을 선택한다. 또 가중 베스트 오브 N은 베스트 오브 N을 발전시킨 형태로, 답변의 일관성을 고려하여 자신감이 높고 자주 나타나는 답을 선택한다.
연구진은 프로세스 보상 모델(PRM)을 사용해 최종 답변뿐만 아니라 답변에 도달하는 과정도 평가했다. 실험 결과, 가중 베스트 오브 N과 PRM을 활용한 '라마-3.2 1B' 는 난이도가 높은 MATH-500 벤치마크에서 '라마-3.2 8B'에 가까운 성능을 보였다.
 |
성능을 더 향상하기 위해 '빔 탐색(beam search)' 알고리즘을 추가했다. 이 방법은 모델이 답변하는 과정을 단계적으로 구분, 각 단계에서 생성된 답변을 탐색 알고리즘이 보상 모델로 평가해 최적의 답을 찾아내는 방식이다.
하지만 빔 탐색은 복잡한 문제에서는 성능을 개선할 수 있지만, 간단한 문제에서는 다른 방식보다 성능이 떨어지는 경향을 보였다. 이를 해결하기 위해 'DVTS(Diverse Verifier Tree Search)'와 '연산 최적화 확장 전략(compute-optimal scaling strategy)'을 추가했다.
DVTS는 잘못된 추론 경로를 피하고 다양한 응답을 찾아내도록 설계된 빔 탐색의 변형이다. 또 연산 최적화 확장 전략은 문제의 난이도에 따라 최적의 추론 방식을 동적으로 선택한다.
이를 통해 라마-3.2 1B 모델은 훨씬 큰 8B 모델의 성능을 앞질렀으며, 3B 모델은 심지어 70B 모델보다 더 나은 결과를 도출했다.
 |
그러나 허깅페이스는 "테스트-타임 스케일링에는 여전히 한계가 있다"라고 밝혔다.
예를 들어, 실험에서는 PRM으로 훈련된 라마-3.1-8B 모델을 사용했으며, 이 모델은 두개의 모델을 병렬로 실행해야 한다는 조건이 따른다. 또 이 기술은 코딩이나 수학처럼 답변을 명확히 평가할 수 있는 문제에서만 성능을 발휘한다.
하지만 추론의 핵심인 테스트-타임 컴퓨팅을 오픈 소스 sLM에도 적용할 수 있도록 기술을 개방한 것은 적지 않은 영향을 미칠 수 있다는 설명이다.
특히 기업의 오픈 소스 모델 활용이 늘어나는 가운데, 이제까지 환각이나 정확도, 비용 문제 등으로 모델 도입을 주저했던 기업에는 도움이 될 수 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>