
 |
네이버 큐의 답변 |
글로벌 빅테크들의 '생성 AI 검색' 경쟁이 본격화한 가운데 네이버의 검색 결과가 구글보다 정확도가 높은 것으로 나타났다. 네이버는 '단계별 추론(multi-step reasoning)' 기술과 신뢰할 수 있는 데이터에 기반해 정확도를 높일 수 있었다는 분석이다.
28일 외신 및 업계에 따르면 구글이 최근 선보인 생성 AI 검색 서비스 'AI 오버뷰(AI Overviews)'의 정확도가 떨어진다는 지적이 제기됐다.
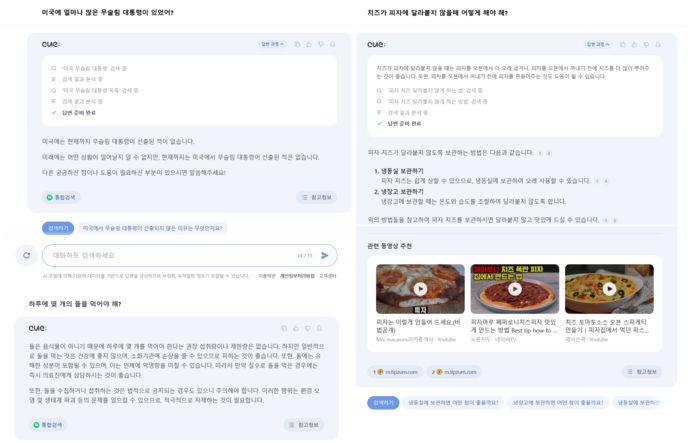
AI 오버뷰는 빠르고 정확한 답변 및 요약까지 AI 기반으로 처리한다는 것이 서비스의 핵심이다. 하지만 오바마가 무슬림 대통령이라고 하거나 △피자에 치즈를 붙이려면 접착제를 사용하라 △건강하려면 하루에 돌을 최소 하나씩은 먹어야 한다 등의 오류 문제가 불거졌다.
구글 관계자는 “현재까지 확인된 많은 사례들은 일반적이지 않은 쿼리가 입력된 경우였다”며 “구글은 자사 콘텐츠 정책에 따라 적절한 조치를 신속하게 취하고 있으며, 그 중 해당 예시들을 활용해 기존 자사 시스템과 이미 출시된 일부 시스템을 개선 중”이라고 밝혔다.
이에 일각에서는 구글이 오픈AI 등과의 속도 경쟁에서 밀리지 않기 위해 AI 오버뷰 서비스 공개를 앞당긴 것이 한 원인이라는 지적도 제기된다.
이에 반해 네이버가 지난해 9월부터 베타 버전을 선보인 생성 AI 검색서비스 '큐(CUE:)'의 답변은 상대적으로 정확했다.
AI 오버뷰에서 문제가 됐던 동일 질문에 네이버 큐는 △미국에서 무슬림 대통령은 없었다 △피자를 더 오래 구워라 △돌을 먹는 것은 건강에 좋지 않다 등 정확도가 높은 답변을 내놨다. 이와 함께 피자에 올라가는 치즈가 달라붙지 않도록 보관하는 방법, 피자 만드는 방법을 알려주는 동영상 등 연관된 정보까지 추천했다.
네이버 큐는 여러 의도가 복잡한 구조로 얽힌 질문도 명확하게 이해한 후 스스로 체계적인 검색을 진행한다. 또 적절한 문서를 바탕으로 답변을 생성 및 요약하고, 쇼핑과 로컬 등 네이버의 다양한 서비스와 연계도 가능하다.
이는 큐가 단계별 추론 과정을 통해 질문 의도를 단계적으로 파악하고 검색 계획을 수립한 후 검색 특화 학습 모델이 여러 단계를 거쳐 검색을 수행하기 때문이다.
큐는 △질의 이해(Reasoning) △답변이 포함된 출처 수집(Evidence Selector) △답변과 출처의 사실성 일치 확인(Factually Consistent Generation) 등 3단계 과정을 통해 환각을 최소화하도록 개발됐다. 내부 자체 테스트 결과 해당 기술 탑재 후 환각 현상이 72% 감소한 것으로 나타났다.
 |
전문가들은 생성 AI의 검색 방식에 따라 정확도가 좌우될 수 있다고 분석했다. AI 오버뷰는 사용자의 질문(쿼리)으로 구글 검색을 한 후 이 결과를 LLM에게 넘겨서 요약한다. 일반적인 질문인 '미국의 수도는 어디인가' 등에 대한 오류가 발생할 확률은 낮다. 검색 결과가 정확하고 이를 요약하는 과정에서의 오류 발생 가능성도 미미해서다.
다만 잘 정리된 질문이 아니거나 논리적이지 않은 질문 등에 대해서는 이같은 검색 방식에 오류를 발생시킬 수 있다는 설명이다. 검색 결과를 LLM에게 넘겨주고 LLM은 이를 충실히 요약하기 때문이다.
전문가들은 AI 검색 정확도를 높이기 위한 방안으로 질문의 유효성 평가와 검색 결과의 유효성 평가 등을 꼽았다.
이재원 넥서스 AI 대표는 “AI가 부족한 혹은 부정확한 검색 결과를 기반으로 답을 생성하려 해 검색의 정확도가 떨어지는 현상이 발생한다”며 “질문이 유효한지에 대한 평가를 선행하고, 검색 결과도 유효한지에 대해 LLM이 하나씩 평가하는 방식 등을 도입한다면 정확도가 높아질 것으로 보이지만 엄청난 연산 비용은 해결 과제”라고 말했다.
손지혜 기자 jh@etnews.com
[Copyright © 전자신문. 무단전재-재배포금지]