
'MoE' 아키텍처로 효율 혁신, 학습 단계 세분화
에이전틱 AI 구현 위한 성능 대폭 향상
엔비디아 A100 수준 범용 GPU에서도 원활하게 구동
에이전틱 AI 구현 위한 성능 대폭 향상
엔비디아 A100 수준 범용 GPU에서도 원활하게 구동
 |
자료ㅣ카카오 |
인더뉴스 이종현 기자ㅣ카카오[035720]가 자체 기술력을 기반으로 개발한 차세대 언어모델 '카나나-2'를 업데이트하고, 4종의 모델을 오픈소스로 추가 공개했다고 20일 밝혔습니다.
'카나나-2'는 지난 12월 허깅페이스를 통해 오픈소스로 공개한 언어모델로 카카오는 한 달여 만에 성능을 크게 업데이트한 4종의 모델을 오픈소스로 추가 공개했습니다.
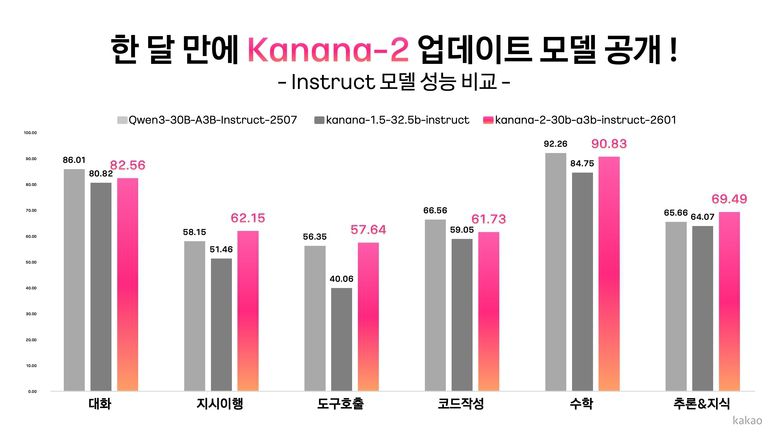
이번에 공개한 4종의 모델은 고효율과 저비용의 성능 혁신은 물론, 실질적인 에이전틱 AI(의 구현을 위한 도구 호출 능력을 대폭 강화한 것이 특징입니다. 특히, 최신 초고가 인프라가 아닌 엔비디아 A100 수준의 범용 GPU에서도 원활하게 구동되도록 최적화해 중소기업과 학계 연구자들도 비용 부담 없이 고성능 AI를 활용할 수 있도록 실용성을 높였습니다.
카나나-2 효율성의 핵심은 '전문가 혼합(MoE)' 아키텍처다. 전체 파라미터는 32B(320억개) 규모로 거대 모델의 높은 지능을 유지하면서도 실제 추론 시에는 상황에 맞는 3B(30억개)의 파라미터만 활성화해 연산 효율을 높였습니다. 또한, MoE 모델의 학습에 필수적인 여러 커널을 직접 개발해 성능 손실 없이 학습 속도는 높이고 메모리 사용량은 획기적으로 낮추는 성과를 거두기도 했습니다.
이러한 아키텍처 및 데이터의 고도화뿐 아니라 데이터 학습 단계도 고도화했습니다. 사전 학습과 사후 학습 사이에 '미드 트레이닝' 단계를 신설하고 AI 모델이 새로운 정보를 배울 때 기존 지식을 잊는 치명적 망각 현상을 방지하기 위해 '리플레이(Replay)' 기법을 도입했습니다. 이를 통해 새로운 추론 능력을 추가하면서도 기존 한국어 구사와 일반 상식 능력을 안정적으로 유지할 수 있었습니다.
카카오는 이러한 기술을 바탕으로 ▲기본 모델부터 ▲지시 이행 모델 ▲추론 특화 모델 ▲미드 트레이닝 모델까지 총 4종의 모델을 허깅페이스에 추가로 공개했습니다. 연구 목적으로 활용도가 높은 미드 트레이닝 탐색용 기본 모델을 함께 제공해 오픈소스 생태계 기여도를 높였습니다.
새로운 카나나-2 모델의 또 다른 차별점은 단순 대화형 AI를 넘어 실질적인 업무 수행이 가능한 에이전트 AI 구현에 특화됐다는 점입니다.
고품질 멀티턴 도구 호출 데이터를 집중 학습시켜 지시 이행과 도구 호출 능력을 대폭 강화함으로써 복잡한 사용자 지시를 정확히 이해하고 적절한 도구를 스스로 선택 및 호출할 수 있도록 했습니다. 실제 성능 평가에서 동급 경쟁 모델인 'Qwen-30B-A3B-Instruct-2507' 대비 ▲지시 이행 정확도 ▲ 멀티턴 도구 호출 성능 ▲ 한국어 능력 등에서 압도적인 우위를 기록했습니다.
김병학 카카오 카나나 성과리더는 "새로워진 카나나-2는 '어떻게 하면 고가의 인프라 없이도 실용적인 에이전트 AI를 구현할 수 있을까'에 대해 치열하게 고민한 결과"라며 "보편적인 인프라 환경에서도 고효율을 내는 모델을 오픈소스로 공개함으로써 국내 AI 연구 개발 생태계 발전과 기업들의 AI 도입의 새로운 대안이 될 수 있기를 기대한다"라고 말했습니다.
한편, 카카오는 현재 MoE 구조를 기반으로 거대 스케일의 수천억 파라미터 모델 '카나나-2-155b-a17b'의 개발을 위한 학습을 진행 중입니다. 특히, 중국의 인공지능 스타트업 '지푸 AI'의 'GLM-4.5-Air-Base' 모델 대비 40% 수준의 데이터로 학습했음에도 MMLU(모델의 일반 지능) 등 주요 벤치마크 성능 지표에서 유사한 성능을 보였습니다.
한국어 질의응답과 수학 영역에서는 압도적 성능 우위를 기록하기도 했습니다. 이 밖에도 기존 LLM(거대언어모델) 학습의 표준인 32비트나 16비트를 대신해 최신 Hopper GPU의 차세대 고효율 포맷인 8비트 방식을 도입해 학습 효율을 극대화하고 있습니다.
향후 카카오는 글로벌 최상위 수준의 성능을 목표로 하는 파운데이션 모델 개발을 이어가고 더 복잡한 에이전트 시나리오에도 대응할 수 있는 고도화된 AI를 선보일 계획입니다.
Copyright @2013~2025 iN THE NEWS Corp. All rights reserved.