
[박찬 기자]
메타가 이미지와 영상에서 어떤 물체든 쉽게 분리해내는 기술로 큰 반향을 일으켰던 '세그먼트 애니싱(SAM)'의 개념을 소리 영역으로 확장했다.
메타는 16일(현지시간) 복잡한 소리 속에서 원하는 음원만 직관적으로 분리해 낼 수 있는 새로운 AI 모델 'SAM 오디오(SAM Audio)'를 공개했다.
SAM 오디오는 하나의 통합 모델로 텍스트, 시각 정보, 시간 구간이라는 세가지 프롬프트 방식을 지원한다.
메타가 이미지와 영상에서 어떤 물체든 쉽게 분리해내는 기술로 큰 반향을 일으켰던 '세그먼트 애니싱(SAM)'의 개념을 소리 영역으로 확장했다.
메타는 16일(현지시간) 복잡한 소리 속에서 원하는 음원만 직관적으로 분리해 낼 수 있는 새로운 AI 모델 'SAM 오디오(SAM Audio)'를 공개했다.
SAM 오디오는 하나의 통합 모델로 텍스트, 시각 정보, 시간 구간이라는 세가지 프롬프트 방식을 지원한다.
사용자는 "개 짖는 소리", "노래하는 목소리"처럼 자연어로 설명하거나, 영상 속 인물이나 악기를 클릭하거나, 특정 시간대를 표시하는 것만으로도 원하는 소리를 분리할 수 있다. 팟캐스트에서 개 짖는 소리만 제거하거나, 공연 영상에서 기타 연주 소리만 따로 추출하는 작업이 가능하다.
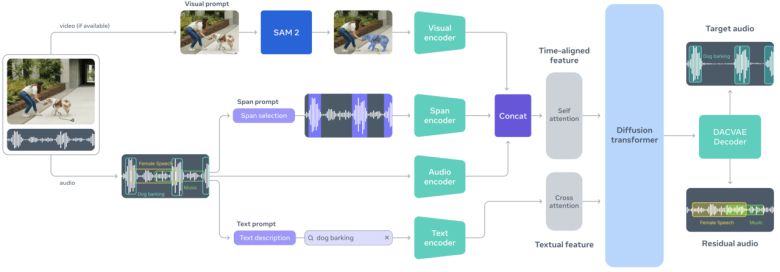 |
기술적으로 SAM 오디오는 여러 입력을 동시에 처리한다.
원본 오디오를 분석하는 오디오 인코더, 텍스트 설명을 이해하는 텍스트 인코더, 시간 정보를 담는 스팬(span) 인코더, 영상과 객체 마스크를 활용하는 비주얼 인코더가 각각 작동한다. 이 정보들은 시간 축에 맞춰 결합한 뒤, 확산 트랜스포머(diffusion transformer)를 거쳐 최종적으로 '타깃 오디오'와 '잔여 오디오' 두개의 결과물로 출력된다. 타깃은 분리한 소리, 잔여는 나머지 모든 소리다.
메타는 이 구조가 실제 편집 작업과 잘 맞는다고 설명한다. 특정 소음을 없애고 싶으면 잔여 오디오만 남기면 되고, 특정 악기나 목소리를 강조하고 싶으면 타깃 오디오를 활용하면 된다. 기존처럼 소리 종류마다 별도 모델을 만들 필요 없이, 모델 하나로 다양한 작업을 처리할 수 있다는 점이 핵심이다.
SAM 오디오는 메타가 공개한 PE-AV(Perception Encoder Audiovisual) 모델을 기반으로 한다. 이 모델은 영상 프레임과 오디오를 시간 단위로 정밀하게 정렬해, '보이는 것'과 '들리는 것'을 함께 이해하도록 돕는다.
이를 통해 화면 속 인물이나 악기와 연결된 소리를 정확히 분리할 수 있다. PE-AV는 1억개 이상의 영상 데이터를 활용해 학습됐으며, 오픈 소스로 공개돼 있다.
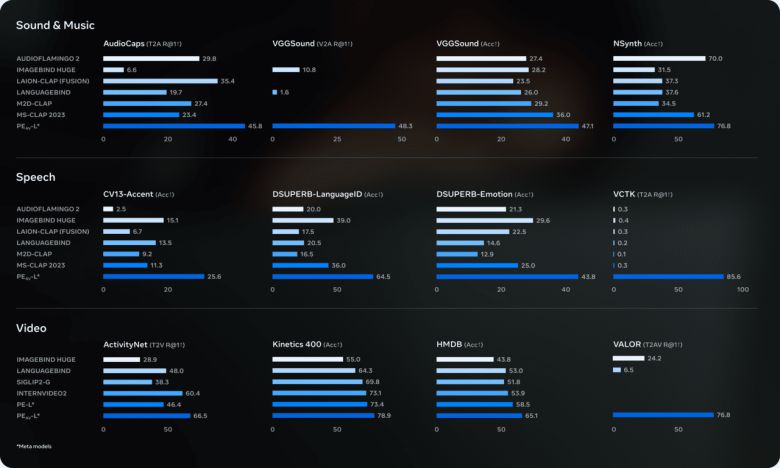 |
성능 평가에서도 경쟁력을 보였다.
메타가 공개한 자체 평가 결과에 따르면, SAM 오디오는 일반 소리, 음성, 음악, 악기 분리 등 다양한 분야에서 기존 최고 수준 모델과 맞먹거나 이를 뛰어넘는 성능을 기록했다. 특히 대형 모델 'SAM 오디오 라지(Large)'는 전문 악기 분리 영역에서 높은 점수를 받았다. 처리 속도 역시 실시간보다 빠른 수준으로, 대규모 편집 작업에도 활용 가능하다.
소리를 프롬프트로 사용하는 기능이나, 아무 조건 없이 완전 자동 분리는 지원하지 않는 등 한계도 있다. 또 합창단에서 특정 한명의 목소리만 분리하는 등 유사한 소리 간 구분은 여전히 어려운 과제로 꼽힌다.
메타는 이와 함께 현실 환경 기반 오디오 분리 벤치마크 'SAM 오디오-벤치'와 사람의 청취 판단을 모방한 자동 평가 모델 'SAM 오디오 저지(Judge)'도 공개했다.
SAM 오디오-벤치는 음성, 음악, 일반 효과음 등 주요 오디오 영역을 모두 포함하는 종합 벤치마크다. 텍스트·시각·스팬 프롬프트를 아우르며, 실제 영상과 음성을 기반으로 구성돼 기존의 합성 데이터 중심 평가보다 현실성이 높다.
샘플에는 시각 마스크와 시간 표시, 명확한 텍스트 설명이 포함돼 다양한 조건에서 모델 성능을 공정하게 비교할 수 있다. 특히 참조 음원 없이도 평가가 가능하도록 설계돼, 원본 오디오 소스가 없는 실제 환경에서도 신뢰도 높은 성능 검증이 가능하다.
SAM 오디오 저지는 사람이 실제로 소리를 듣고 판단하는 방식에 가깝게 오디오 분리 품질을 평가하도록 설계된 새로운 평가 모델이다. 기존처럼 분리된 음원을 정답 음원과 직접 비교하는 방식이 아니라, 참조 음원 없이도 분리 결과의 품질을 객관적으로 판단할 수 있는 것이 특징이다.
이 모델은 정확도, 재현율, 충실도, 전반적 품질 등 9가지 지각적 기준을 바탕으로 학습됐으며, 인간 평가 데이터를 활용해 청각적 인식에 맞는 판단을 수행한다.
SAM 오디오, SAM 오디오-벤치, SAM 오디오 저지는 깃허브에서 다운로드 할 수 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>