
[박찬 기자]
'완전 오픈 소스'로 유명한 앨런 AI 연구소(Ai2)가 대표 대형언어모델(LLM)인 '올모(OLMo) 3'의 업데이트 버전을 공개했다. 지난달 20일 출시한 모델을 개선한 '체크포인트(Checkpoint)'를 추가 공개한 것이다.
Ai2는 12일(현지시간) 올모 3에 강화 학습(RL)을 추가 적용해 성능을 향상한 플래그십 모델 올모 3.1 싱크 32B(Olmo 3.1 Think 32B) 올모 3.1 인스트럭트 32B(Olmo 3.1 Instruct 32B)를 공개했다.
올모 3는 '완전 개방형(Fully Open)' 모델로, 훈련 데이터와 가중치 등을 전면 공개해 개발자나 기업이 모델 학습 과정을 완전히 통제할 수 있도록 했다.
 |
'완전 오픈 소스'로 유명한 앨런 AI 연구소(Ai2)가 대표 대형언어모델(LLM)인 '올모(OLMo) 3'의 업데이트 버전을 공개했다. 지난달 20일 출시한 모델을 개선한 '체크포인트(Checkpoint)'를 추가 공개한 것이다.
Ai2는 12일(현지시간) 올모 3에 강화 학습(RL)을 추가 적용해 성능을 향상한 플래그십 모델 올모 3.1 싱크 32B(Olmo 3.1 Think 32B) 올모 3.1 인스트럭트 32B(Olmo 3.1 Instruct 32B)를 공개했다.
올모 3는 '완전 개방형(Fully Open)' 모델로, 훈련 데이터와 가중치 등을 전면 공개해 개발자나 기업이 모델 학습 과정을 완전히 통제할 수 있도록 했다.
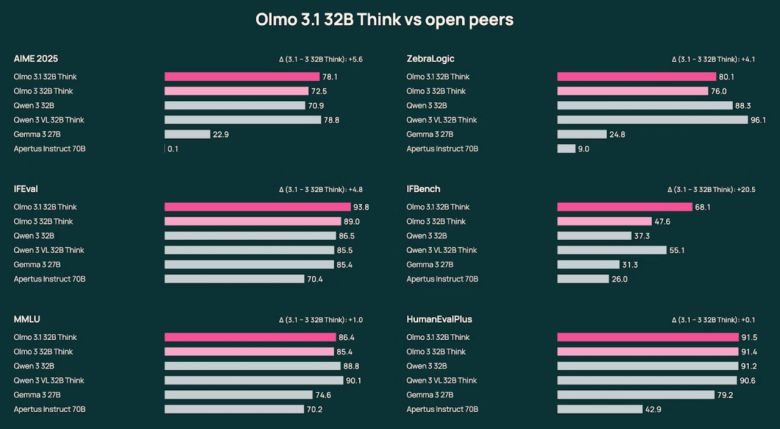
여기에 새로 공개한 싱크 32B는 고급 추론과 연구 목적에 최적화했다. 이번에는 이전 버전에 RL 과정을 21일간 추가로 연장해, 224개의 GPU를 활용한 장기 학습을 거쳤다.
이 과정에서 수학, 추론, 지시 이행 능력이 크게 향상됐으며, AIME, 지브라로직(ZebraLogic), IF이벨, IF벤치 등 주요 벤치마크에서 의미 있는 점수 상승을 기록했다. 코딩과 복잡한 다단계 작업에서도 성능이 개선됐다.
인스트럭트 32B는 소형 모델인 인스트럭트 7B에 적용했던 학습 레시피를 대형 모델로 확장해 개발됐다. 지시 이행, 멀티턴 대화, 도구 사용 등 실사용 환경을 겨냥했다.
대화형 AI와 툴 기반 워크플로에 최적화된 구조로, 현재까지 공개된 완전 오픈 소스 32B급 지시형 모델 중 가장 강력한 성능을 갖췄다고 평했다. 실제로 수학 벤치마크에서는 '젬마(Gemma)' 계열 모델을 상회하는 결과를 보였다.
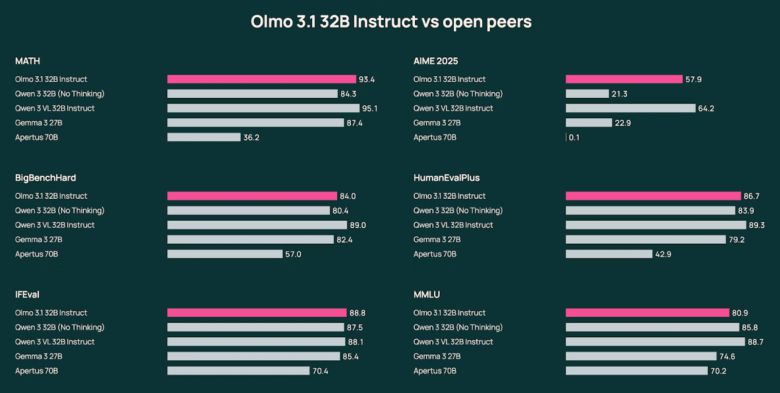 |
성능 비교에서도 올모 3.1은 경쟁 모델들과 어깨를 나란히 했다.
싱크 32B는 AIME 2025에서 '큐원 3 32B'를 앞섰고, '젬마 27B'에 근접한 성능을 기록했다. 이는 오픈 모델이면서도 상용 수준의 경쟁력을 확보했음을 보여준다는 평이다.
이와 함께 Ai2는 수학·코딩 특화 모델인 'RL-Zero 7B'도 학습 안정성과 기간을 늘려 성능을 개선했다.
 |
Ai2는 올모 시리즈를 처음부터 기업과 연구기관이 데이터 구성과 학습 과정을 직접 이해하고 통제할 수 있도록 설계해 왔다.
이번에도 새로운 모델 출시라기 보다, 체크포인트를 추가했다는 개념으로 소개했다. 체크포인트는 모델의 학습 과정 중 특정 시점의 상태를 저장해 둔 파일과 데이터 집합을 의미한다.
이를 통해 개발자들이 자유롭게 자체 데이터를 추가해 재학습할 수 있도록 지원한 것이다. 또 '올모트레이스(OlmoTrace)' 도구를 통해 모델 출력이 어떤 학습 데이터와 연관되는지도 추적할 수 있다.
Ai2는 "현재까지 가장 뛰어난 성능을 자랑하는 두개의 새로운 32B 체크포인트를 완성, 개방성과 성능이 동시에 발전할 수 있음을 보여준다"라고 밝혔다. 또 "동일한 모델 흐름을 확장함으로써 데이터, 코드 및 학습 결정에 대한 엔드투엔드 투명성을 유지하면서 기능을 지속적으로 개선했다"라고 강조했다.
올모 3.1 모델들은 현재 Ai2 플레이그라운드와 허깅페이스를 통해 체크포인트 형태로 제공되고 있으며, API 접근도 조만간 지원될 예정이다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>