
[박찬 기자]
오픈AI가 별도의 실시간 음성 인공지능(AI) 모델을 출시했다. 이는 기업용 음성 AI 애플리케이션 시장을 타깃으로 한 것이다.
오픈AI는 29일(현지시간) 새로운 음성 모델 'gpt-리얼타임(gpt-realtime)'과 '리얼타임 API(Realtime API)'를 공식 출시했다.
gpt-리얼타임을 "가장 진보된 실제 서비스에 즉시 적용 가능한 음성 모델"이라고 소개했다.
 |
오픈AI가 별도의 실시간 음성 인공지능(AI) 모델을 출시했다. 이는 기업용 음성 AI 애플리케이션 시장을 타깃으로 한 것이다.
오픈AI는 29일(현지시간) 새로운 음성 모델 'gpt-리얼타임(gpt-realtime)'과 '리얼타임 API(Realtime API)'를 공식 출시했다.
gpt-리얼타임을 "가장 진보된 실제 서비스에 즉시 적용 가능한 음성 모델"이라고 소개했다.
기존 음성 AI가 음성 인식(STT), 언어 처리, 음성 합성(TTS) 단계를 거치는 파이프라인 방식이었다면, gpt-리얼타임은 음성을 직접 처리하는 단일 구조를 채택했다는 것이다. 이는 모델의 지연을 줄이고 억양이나 호흡, 웃음 같은 비언어적 신호까지 인식할 수 있다.
또 다국어 지원은 물론, 대화 중 언어 전환이나 특정 억양을 요구하는 지시도 수행할 수 있다. 오픈AI는 기업과의 협력을 통해 고객 상담이나 학습 지도 등 실제 사용 환경을 반영해 모델을 훈련했다고 밝혔다.
동시에, 새로 출시한 리얼타임 API에는 기업 환경에서 활용성을 크게 높일 수 있도록 통합 기능을 강화했다.
우선 SIP(세션 개시 프로토콜) 지원을 통해 AI 상담원이 기존 전화망이나 PBX 시스템과 직접 연결될 수 있어, 고객 센터나 콜센터 같은 실무 환경에 바로 적용할 수 있다. 또 MCP(Model Context Protocol) 지원으로 외부 도구와 서비스 연동이 간소화, 개발자가 별도의 복잡한 작업 없이 다양한 기능을 통합할 수 있게 됐다.
또 이미지 입력 기능도 추가, 사용자가 스크린샷이나 사진을 공유하면 AI가 이를 바탕으로 실시간 설명을 제공할 수 있다.
비동기 함수 호출 기능도 더해져, API 호출이나 데이터베이스 질의 등 시간이 걸리는 작업이 진행되는 동안에도 대화 흐름을 끊김 없이 이어갈 수 있게 됐다.
 |
오픈AI는 새 모델의 성능 지표를 공개하며 개선된 결과를 강조했다.
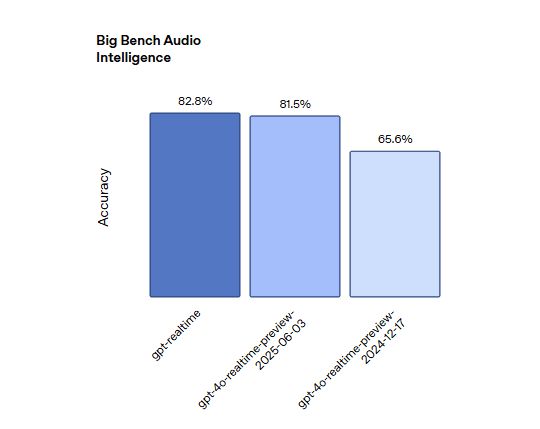
우선 '빅 벤치 오디오(Big Bench Audio)' 평가에서 정확도가 82.8%를 기록해, 이전 모델의 65.6%에 비해 큰 향상을 입증했다.
'멀티챌린지(MultiChallenge)' 오디오 벤치마크에서는 정확도가 30.5%로 집계돼, 기존 20.6% 대비 뚜렷한 개선을 입증했다. '복합 함수 호출(ComplexFuncBench)' 성능도 과거 49.7%에서 66.5%까지 끌어 올렸다.
가격 경쟁력도 강화했다. 입력 100만 오디오 토큰당 32달러, 출력 64달러로 기존보다 20% 가격을 인하했다. 이는 경쟁사의 저가 공세에 맞서 시장 점유율 확대를 노린 전략이다.
실제로 음성 AI 시장은 빅테크와 전문 스타트업들이 치열한 경쟁을 펼치고 있다. 일레븐랩스는 5월 '컨버세이션 AI 2.0'을 발표했고, 사운드하운드는 패스트푸드 업계에 드라이브스루용 음성 AI를 공급 중이다. 흄(Hume)은 사용자 목소리를 그대로 복제하는 'EVI 3'를 출시했다.
구글은 '노트북LM'에 오디오 기능을 강화하며 연구 메모를 팟캐스트로 변환하는 기능을 제공하고 있고, 미스트랄은 실시간 번역에 초점을 맞춘 '복스트랄(Voxtral)' 모델을 공개한 바 있다. 마이크로소프트도 최근 4명의 다른 화자의 음성을 최대 90분까지 합성할 수 있는 오픈 소스 텍스트 음성 변환 모델 '바이브보이스-1.5B(VibeVoice-1.5B)'를 출시했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>