
[딜라이트닷넷 창간 15주년] 칩 가격·전력비 절감 요구 UP…sLM 주목도 커져
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
반도체 업계는 이러한 기조에 맞춰 AI칩 성능 고도화를 지속하는 한편, 데이터센터의 총소유비용(TCO)을 절감하기 위한 다양한 솔루션을 개발하고 있다. 이에 따라 원가 절감의 핵심으로 주목받는 칩렛(Chiplet)을 비롯해 소규모언어모델(sLM)을 노린 AI가속기, 차세대 고속 인터페이스 프로토콜인 컴퓨트익스프레스(CXL) 등이 주목받는 모양새다.
데이터센터에서 AI를 구현하는 영역은 크게 두가지다. 첫째는 막대한 데이터를 알고리즘으로 지식을 습득해 AI 모델을 만드는 학습(Learning), 둘째는 학습한 모델을 통해 입력된 기능을 구현하는 추론(Inference)이다. 초거대언어모델(LLM)을 구축하는 과정이 학습에 해당하며, 이를 기반으로 챗봇·통화 번역·금융 등 각종 서비스를 구현하는 것이 추론이다.
기존에는 학습용 분야가 AI 데이터센터의 대부분을 차지해왔다. AI 서비스 구현을 위한 토대를 다져야 하는 시기를 거쳐왔기 때문이다. 이 과정에서 엔비디아가 쿠다(CUDA)·그래픽저장장치(GPU)·NV링크 및 NV스위치 등 다양한 생태계 저변을 바탕으로 앞서나갔고, 현재까지도 AI 반도체 시장 내 우위를 굳건히 유지하고 있다.
하지만 최근에는 상황이 달라지고 있다. AI 데이터센터 구축에 따른 비용이 점점 증가하면서 엔비디아 외 반도체 기업을 택하려는 움직임이 늘어나고 있다. 엔비디아의 칩과 AI 서버 구축 솔루션이 대규모 투자 비용을 요구하는 데다, 유지비용 측면에서도 높은 전력 소모에 따른 단점이 부각되고 있는 탓이다. 학습 대비 요구 성능이 낮은 추론용 서버 투자가 늘어나는 점도 이러한 추세에 기여하는 모습이다.
이미 주요 하이퍼스케일 기업들은 자체 ASIC 개발을 활발히 추진 중이다. 구글은 AI 전용 칩인 텐서처리장치(TPU)를 지속 개발하며 추론에 이어 학습용 칩까지 범위를 넓히고 있으며, 마이크로소프트(MS)도 '애저 마이아'를 출시하는 한편 추론 전용칩 '아테나'를 개발하고 있다. 아마존웹서비스(AWS)는 학습용 칩 '트레이니움'을 2세대까지 출시했고 추론용 칩 '인퍼런시아'의 차세대 제품을 개발 중이다.
AI 추론용 칩 시장을 진입하기 위한 반도체 업계의 칩 개발도 눈에 띈다. 인텔이 추론·학습용 칩 '가우디3'를 개발하며 관련 시장 진입을 노리고 있고, AMD도 MI300 등의 성과를 바탕으로 MI325 등을 내놓는 계획을 세웠다.
ASIC 확대에 따라 반도체 설계자산(IP) 기업 Arm, 그리고 오픈소스형 반도체 IP 생태계인 리스크파이브(RSIC-V)의 가치도 수직상승했다. 이들의 반도체 IP는 저전력 설계에 유리했던 탓에 서버·데이터센터에서는 고전을 면치 못했지만, 높은 총소유비용(TCO)을 절감키 위한 시도가 늘면서 다시금 주목 받게 됐다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
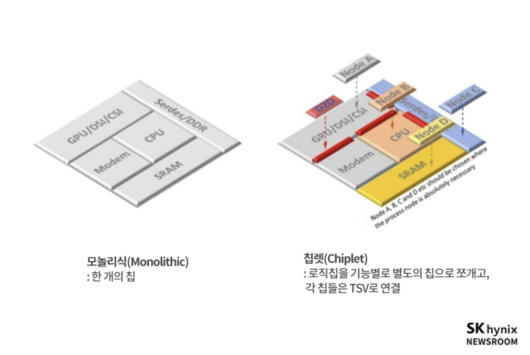
높은 칩 생산 비용을 해결하기 위한 대안으로 나온 것이 칩렛(Chiplet)이다. 칩렛은 여러개 기능을 각자 최적화된 공정에서 생산하고 하나로 합치는 방식을 의미한다. 이를 활용하면 SoC 내 고성능으로 제작할 필요가 없는 아날로그 기능을 성숙 공정으로 제작할 수 있다. 그만큼 칩 크기는 커지지만, 단일 SoC 대비 높은 성능을 낮은 비용으로 제작할 수 있게 된다.
이미 이 기술은 상용화에서 진척을 이루고 있다. AMD가 지난해 12월 AI칩 'MI300X'를 칩렛으로 개발했고, 엔비디아 역시 차세대 AI칩 'B200'를 칩렛 구조로 내놨다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
sLM은 LLM처럼 모든 데이터를 취합해 서비스를 제공하는 것이 아닌, 특정 영역에만 한정된 데이터를 학습해 서비스할 수 있도록 설계된 AI 모델이다. 용량은 LLM(400GB 이상) 대비 크게 낮춘 50~80GB 내외로 추정된다. 용량이 적은 만큼 LLM이 담당하는 영역을 모두 서비스할 순 없으나 여러개 sLM을 병용·통합해 활용하는 안이 논의되고 있다. 이러한 sLM용 서버 구조를 갖추려면 ▲sLM을 저장하는 SSD ▲이를 연산처리하는 AI가속기 ▲시스템을 총괄하는 CPU가 유기적으로 신호를 전달받는 시스템을 구축해야 하는데, 이를 가능케 하는 요소로 CXL이 주목받은 것이다.
반도체 업계에서는 CXL을 기반으로 데이터센터를 구축하면 빠른 데이터 처리를 위한 NV링크·NV스위치 등 고비용 솔루션이 필요없고, 데이터센터 랙(Rack) 설계 자유도가 늘어나 구축 비용도 절감할 수 있을 것으로 봤다.
현재 CXL 시장은 인텔이 CXL 2.0 관련 생태계를 넓히고 있으며, 하이퍼스케일의 참여에 따라 오는 2026년부터 CXL 3.0 이상의 데이터센터 구축이 예고된 상황이다. 미국 글로벌 팹리스인 브로드컴은 자체 PCIe 기술 경쟁력을 바탕으로 CXL 스위치를 개발하고 있으며, 지난 3월 나스닥에 상장한 아스테라 랩스가 CXL 인터커넥트 솔루션 상용화에 나섰다.
국내 기업 중에서는 파네시아가 CXL 3.1 원천 기술을 확보한 후 종단간(End to End) 솔루션 개발을 진행하고 있다. 내년 하반기에는 CXL 스위치를 고객사에 제공하겠다는 목표를 내세웠다. 파두 자회사인 이음도 2026년 양산을 목표로 CXL 스위치를 개발하고 있다.
글로벌 양대 메모리 기업인 삼성전자와 SK하이닉스도 CXL 인터페이스에 맞춰 용량을 확대한 D램 모듈을 개발하고 있다. 삼성전자는 CXL 2.0 기반 256기가바이트(GB) 모듈인 CMM-D를 연내 양산할 계획이며, SK하이닉스도 올해 하반기 상용화를 목표로 96GB, 128GB CXL 2.0 모듈을 개발하고 있다.
- Copyright ⓒ 디지털데일리. 무단전재 및 재배포 금지 -
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
