
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
증강현실(AR) 안경을 착용하고 메타버스의 파티에서 어울리거나 거실에서 홈 무비를 볼 때 음향은 몰입감을 높이고 사실적인 경험을 하는데 중요한 역할을 한다. 메타(Meta)는 이러한 환경을 혼합현실(XR)과 가상현실(VR)에서 제공하기 위해 실제 환경과 일치하는 사실적인 음질을 제공하는 AI 모델을 구축하고 있다.
예를 들어 콘서트가 큰 장소에서 들리는 것과 거실에서 들리는 것 사이에는 큰 차이가 있다. 물리적 공간의 구조, 공간 구조물의 재질 및 표면, 소리가 나오는 위치 등의 요인들이 소리가 어떻게 들리는지를 결정하기 때문이다.
메타의 리얼리티 랩(Reality Labs)과 텍사스 오스틴 대학(University of Texas, Austin)의 연구원들이 공간의 물리적 환경에 따라 사람의 말과 비디오의 소리가 어떻게 들릴지에 대한 시청각 이해를 위해 3가지 새로운 AI 모델을 공개했다.
시각 음향 매칭(Visual Acoustic Matching) 모델의 경우 대상 환경의 이미지에 녹음된 오디오 클립을 입력하고 해당 환경에서 녹음된 것처럼 들리도록 클립을 변환할 수 있다. 예를 들어 이 모델은 동굴에서 녹음된 음성 오디오와 함께 레스토랑의 식당 이미지를 찍고 그 음성이 사진에 있는 레스토랑에서 녹음된 것처럼 만들 수 있다.
두 번째 모델인 시각 정보 기반 잔향 제거(Visually-Informed Dereverberation) 모델은 관찰된 소리와 공간의 시각적 신호를 사용해 녹음된 환경에 따라 소리가 만드는 잔향(echo)을 제거한다. 이 모델은 바이올린 콘서트가 열리는 기차역에서 기차역 주변에서 울려 퍼지는 잔향 없이 바이올린 소리를 추출할 수 있다.
세 번째 모델인 비주얼보이스(VisualVoice)는 시각적 및 청각적 신호를 사용해 음성을 다른 배경 소리나 배경 음성과 분리한다. 이것은 더 나은 자막을 만들거나 VR에서 파티에 어울리는 음악을 제공한다.
오디오가 장면과 일치하지 않는 비디오를 보게 되면 사람은 어지러움과 같은 통증을 느낄 수 있다는 연구조사가 있다. 인간의 인식에 큰 방해를 주기 때문이다. 하지만 과거에는 서로 다른 환경의 오디오와 비디오를 일치시키는 것은 어려운 과제였다.
이번에 메타가 개발한 AViTAR 모델은 이 어려움을 줄여줄 수 있다. 시각 음향 매칭 모델은 대상 이미지의 공간에 맞게 오디오를 조정한다. 입력이 이미지와 오디오로 구성된 교차 모드 변환기(cross-modal transformer) 모델을 사용해 변환기가 상호 모드 추론을 수행하고 시각적 입력과 일치하는 사실적인 오디오 출력을 생성할 수 있도록 한다.
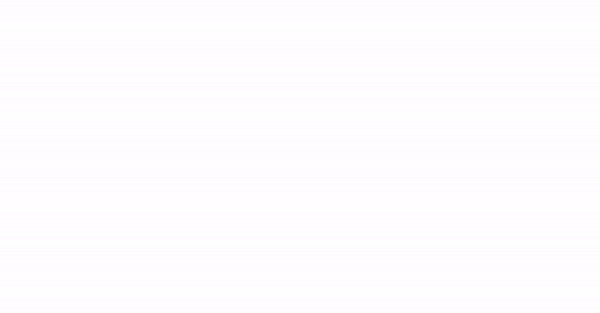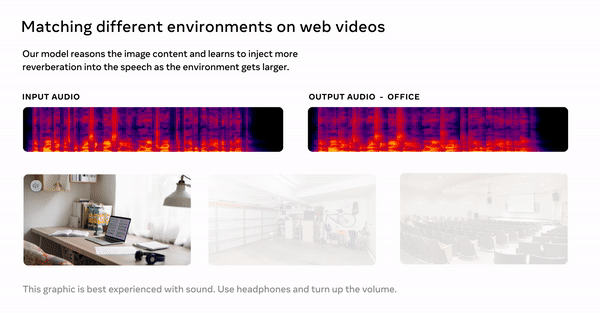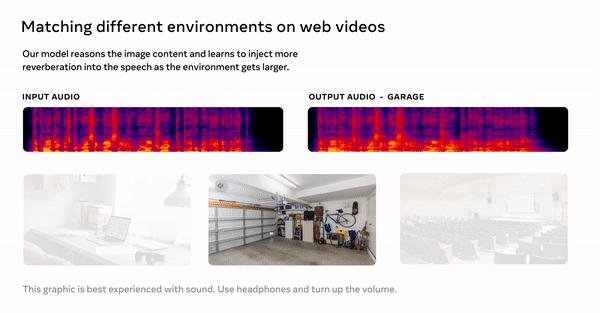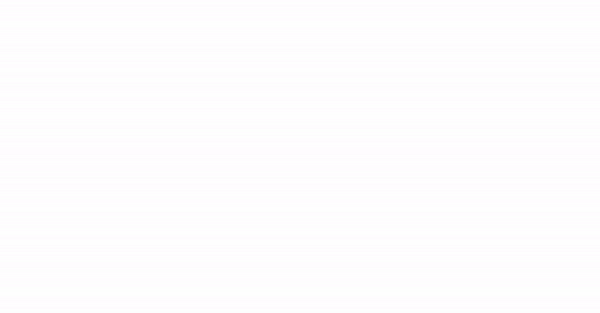 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
오픈 소스 Replica 및 Matterport3D 데이터 세트의 모든 음원에 대해 사실적인 시뮬레이션을 삽입해 만든 오디오 렌더링 데이터 세트인 사운드스페이스(SoundSpace)와 공개적으로 사용 가능한 29만 개의 영어 비디오에서 말하는 사람들의 3~10초 클립으로 구성된 데이터 세트를 사용했다. 두 데이터 세트 모두 실내 설정의 음성에 초점을 맞췄다. 마이크와 카메라는 음원에서 멀리 떨어져 있어야 한다. 이것은 소리가 나는 곳과 사람이나 마이크의 위치에 따라 소리가 다르게 들릴 수 있기 때문에 중요했다.
수집한 웹 비디오에서 극복해야 하는 한 가지 문제는 대상 환경의 음향과 일치하는 오디오만 있다는 것이었다. 이 문제를 해결하기 위해 먼저 잔향을 제거한 다음 오디오를 다른 환경의 임펄스 응답(impulse response)과 얽히게 해 음향을 무작위로 만들고 노이즈를 추가하여 내용은 같지만 음향이 다른 오디오를 만들었다.
두 데이터 세트에서 모델을 검증하고 생성된 오디오의 품질을 실제와 일치성, 실내 음향의 정확성, 합성된 음성의 품질 등의 세 가지 기준으로 측정했다. 또한 인간 청취자에게 음향이 참조 이미지와 일치하는지 평가하도록 요청해서 모델이 사람의 말을 이미지에 묘사된 다양한 실제 환경으로 성공적인 변환을 한다는 결과를 얻었다.
시각 음향 매칭 모델의 기대되는 미래 사용 사례는 과거 기억을 되살리는 것이다. 예를 들어 AR 안경을 쓰고 자녀의 발레 공연의 홀로그램을 보는 것과 같이 관련된 기억을 재생할 수 있다. 오디오는 잔향을 제거하고 청중의 자리에 앉아 경험했던 것과 같은 기억 사운드를 만든다.
 |
시각 음향 매칭으로 잔향을 추가하는 것이 도움이 되는 경우도 있지만, 청력과 이해를 향상시키기 위해 잔향을 제거해 반대 작업을 수행해야 하는 설정도 있다. 잔향은 환경의 표면과 물체에 반사되어 사람이 인지할 수 있는 음성 품질을 저하시키고 자동 음성 인식의 정확도에 심각한 영향을 미친다. 잔향을 제거함으로써 음성을 더 쉽게 인식하도록 향상시킬 수 있다. 예를 들어 자동 음성 인식이 청력 손실이 있는 사람들을 위해 보다 정확한 자막을 생성하는 데 도움이 된다.
이전 접근 방식은 오디오 양식에만 기반해 잔향을 제거하려고 시도했지만 이것이 환경의 완전한 음향 특성을 알려주지는 않는다. 블라인드 잔향 제거는 잔향을 제거하기 위해 주변 환경을 고려하지 않고 언어에 대한 사전 지식에 의존한다. 이것이 시각적 관찰이 필요한 이유다.
VIDA(Visually-Informed Dereverberation of Audio) 모델은 관찰된 소리와 시각적 스트림을 기반으로 반향을 제거하는 방법을 학습해 공간의 구조, 공간 구조물의 재질 및 스피커 위치 등 오디오 스트림에서 들리는 잔향 효과에 영향을 미치는 요소에 대한 신호를 보여준다. 이 경우 특정 위치에서 잔향 오디오를 가져와서 공간의 미치는 음향 효과를 제거한다. 이를 위해 사운드스페이스 작업을 기반으로 음성의 사실적인 음향 렌더링을 사용하는 대규모 교육 데이터 세트를 개발했다.
 |
세 번째 모델인 비주얼보이스는 듣기뿐만 아니라 보기를 통해 음성을 이해한다. 이것은 인간과 기계의 인식을 개선하는 데 중요하다. 사람들이 복잡한 환경에서 말을 이해하는 데 AI보다 더 나은 한 가지 이유는 우리가 귀뿐만 아니라 눈도 사용하기 때문이다. 예를 들어, 누군가의 입이 움직이는 것을 보고 우리가 듣고 있는 목소리가 그 사람에게서 나오는 것이 틀림없다는 것을 직관적으로 알 수 있다. 이것이 인간과 마찬가지로 대화에서 보는 것과 듣는 것 사이의 미묘한 상관 관계를 인식할 수 있는 비주얼보이스 모델을 개발하는 이유다.
비주얼보이스는 레이블이 지정되지 않은 비디오에서 시각 및 청각 신호를 학습해 시청각 음성 분리를 달성함으로써 사람들이 새로운 기술을 다중 모드로 습득하는 것과 유사한 방식으로 학습한다. 기계의 경우 더 정확한 캡션을 만드는 것과 같이 더 나은 인식을 한다. 인간의 인식도 향상된다. 예를 들어, 메타버스에서 전 세계의 동료들과 그룹 회의에 참석해 사람들과 대화를 하고 서로 수다를 떨면서 가상 공간을 이동하고 작은 그룹에 합류할 때 마다 잔향과 음향이 그에 따라 조정되는 것을 경험할 수 있다.
이러한 모델을 함께 사용하면 콘서트, 붐비는 파티 또는 기타 시끄러운 장소 등 어떤 상황에서도 스마트 비서가 우리가 말하는 내용을 들을 수 있게 된다.
기존 AI 모델은 이미지를 잘 이해하고 있고, 영상 이해도 점점 좋아지고 있다. 그러나 AR 및 VR을 위한 새롭고 몰입감 있는 경험을 구축하려면 오디오, 비디오 및 텍스트 신호를 동시에 수신하고 환경에 대한 훨씬 더 풍부한 이해를 생성할 수 있는 다중 모드 AI 모델이 필요하다.
AViTAR 및 VIDA는 현재 단일 이미지를 기반으로 하고 있지만 메타는 앞으로 공간의 음향적 특성을 포착하기 위해 비디오 및 기타 역학을 사용하여 탐구할 계획이다. 이를 통해 실제 환경과 사람들이 경험하는 방식을 이해하는 다중 모드 AI를 생성하려는 목표에 더 가까이 다가갈 수 있다.
메타는 혼합 및 가상 현실 경험에서 사운드를 더욱 사실적으로 만들기 위한 음향 합성 AI 모델을 설계했다.(영상=메타)AI타임스 박찬 위원 cpark@aitimes.com
[관련기사]메타, 명품 아바타 스토어 출시
[관련기사]메타버스로 현실 세계 더 풍성하게 만든다
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
